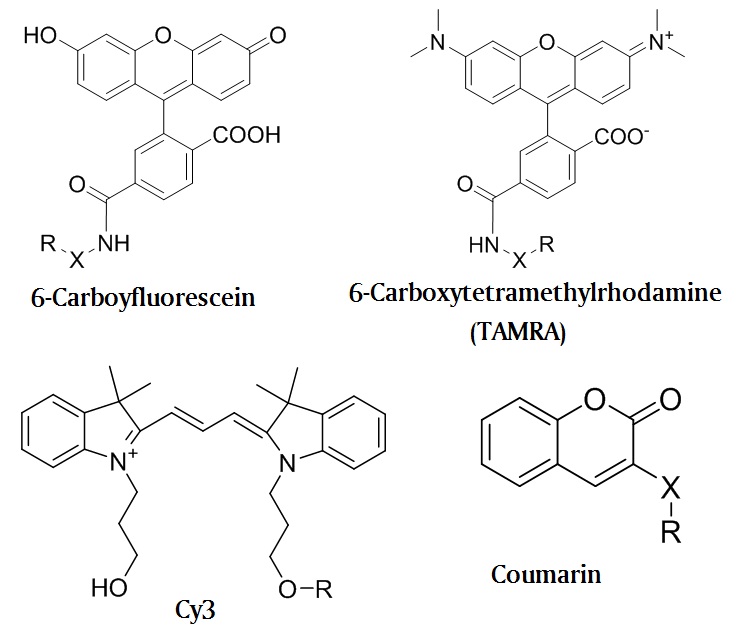
The Ebola Virus Genome and Proteome
The Ebola virus is a single-stranded, negative-sense mini-genome RNA virus. Zaire Ebola virus is responsible for the recent outbreak in West-Africa. Ebola viruses belong to the filoviridae family, and together with Paramyxoviridae, Rhabdoviridae, and Borna disease virus, Filoviridae viruses belong to the taxonomic order mononegavirales.
Mononegavirales is the term used for "nonsegmented negative-strand RNA viruses" (NNSV). These are enveloped viruses that have mini-genomes consisting of a single RNA molecule of negative or anti-mRNA sense.
Nucleic acids isolated from negative strand RNA viruses or virus-infected cells cannot infect or initiate an infection cycle when introduced into the host cell. This criterion was used to distinguish “positive’ from “negative”-strand RNA viruses. The viral genome needs to be first transcribed to produce mRNAs. Therefore, the purified virion RNA is not infectious. The virus needs to bring its own RNA polymerase into the cell in order to produce mRNA. To allow the virus to be infective a viral polymerase must be part of the viral particle or virion.
The use of non-infectious synthetic viral RNA allows for the design of PCR primers or probes as well as peptides and recombinant proteins for molecular diagnostics. Similarly, these molecules may lend themselves for the design and production of vaccines against the virus.
Features of the unsegmented genome of negative-stranded RNA viruses are:
- Negative sense RNA in the virion
- Virion-associated RNA polymerase mediates transcription and replication
- Genome transcribed into 6-10 separate mRNAs from a single promoter
- Replication occurs by synthesis of a complete positive-sense RNA antigenome
- Nucleoprotein is the functional template for synthesis of replicative and mRNA
- Independently assembled nucleocapsids are enveloped at the cell surface at sites containing virus proteins
- Are mainly cytoplasmic
- Can occur in invertebrates, vertebrates and plants
Features of the family Filoviridae are:
- Filamentous forms with branching; sometimes U-shaped, 6-shaped or circular
- Uniform diameter of 80 nm and varying lengths up to 14,000 nm. Infectious particle length is 790 nm for Marburg virus and 970 nm for Ebola virus
- Surface spikes of 10 nm length
- Helical nucleocapsid; 50 nm diameter, with an axial space of 20 nm diameter and helical periodicity of about 5 nm
- Filamentous with a linear ~13-19 kb mini-genome with a negative-sense single-stranded RNA of molecular weight (Mr) = 4.2 x 106
- At least five (5) proteins; a large (polymerase) protein, a surface glycoprotein, two (2) nucleocapsid-associated proteins, and at least one other protein of unknown function
- Biology enigmatic; only two antigenically unrelated viruses known; blood borne infection of humans and monkeys
Filoviruses are responsible for newly emerging infections. Filoviruses are considered as Biosafety Level 4 agents, in comparison HIV is only considered as Biosafety Level 2+. Filoviruses can infect mice, hamsters, guinea pigs and monkeys. However, it is not known at presence where the virus originates in the wild.
Most human epidemics appear to be blood-born spread, in hospitals often transmitted via contaminated needles, and transmitted via close contact with infected persons or their body fluids. Primary infections with Marburg and Ebola are usually 25 to 90% fatal. Death is thought to occur because of visceral organ necrosis, for example of the liver, due to viral infection of tissue parenchymal cells.
Viral RNA is not infectious by itself. Therefore, the use of cloned or synthetic viral RNA can be very useful for the development and production of diagnostic tests or the development of vaccines against filoviruses, for example, the Ebola virus.
Research with the aim to develop a vaccine for Ebola has already been started for several years now. In 1998, the first immunization for Ebola virus infections that was successful was reported.
“Abstract: Infection by Ebola virus causes rapidly progressive, often fatal, symptoms of fever, hemorrhage and hypotension. Previous attempts to elicit protective immunity for this disease have not met with success. We report here that protection against the lethal effects of Ebola virus can be achieved in an animal model by immunizing with plasmids encoding viral proteins. We analyzed immune responses to the viral nucleoprotein (NP) and the secreted or transmembrane forms of the glycoprotein (sGP or GP) and their ability to protect against infection in a guinea pig infection model analogous to the human disease. Protection was achieved and correlated with antibody titer and antigen-specific T-cell responses to sGP or GP. Immunity to Ebola virus can therefore be developed through genetic vaccination and may facilitate efforts to limit the spread of this disease.”
{Xu L, Sanchez A, Yang Z, Zaki SR, Nabel EG, Nichol ST, Nabel GJ.; Immunization for Ebola virus infection. Nat Med. 1998 Jan;4(1):37-42.}
The result – a DNA vaccine encoding the glycoprotein (sGP or GP) of the Ebola virus evoked a T-cell based immune response in guinea pigs and protected the animals against infection. Further studies indicated that a DNA vaccine can is useful for vaccination. The use of DNA immunization together with adenovirus vectors encoding viral proteins in nonhuman primates resulted in the protection of crab-eating or cynomolgus macaques (Macaca fascicularis) from the lethal pathogen, the wild-type Zaire virus.
“Abstract: Outbreaks of haemorrhagic fever caused by the Ebola virus are associated with high mortality rates that are a distinguishing feature of this human pathogen. The highest lethality is associated with the Zaire subtype, one of four strains identified to date. Its rapid progression allows little opportunity to develop natural immunity, and there is currently no effective anti-viral therapy. Therefore, vaccination offers a promising intervention to prevent infection and limit spread. Here we describe a highly effective vaccine strategy for Ebola virus infection in non-human primates. A combination of DNA immunization and boosting with adenoviral vectors that encode viral proteins generated cellular and humoral immunity in cynomolgus macaques. Challenge with a lethal dose of the highly pathogenic, wild-type, 1976 Mayinga strain of Ebola Zaire virus resulted in uniform infection in controls, who progressed to a moribund state and death in less than one week. In contrast, all vaccinated animals were asymptomatic for more than six months, with no detectable virus after the initial challenge. These findings demonstrate that it is possible to develop a preventive vaccine against Ebola virus infection in primates.”
{Sullivan NJ, Sanchez A, Rollin PE, Yang ZY, Nabel GJ.; Development of a preventive vaccine for Ebola virus infection in primates. Nature. 2000 Nov 30;408(6812):605-9.}
Results from sequence analysis of Ebola viruses from outbreaks in 1976 and 1995 showed a high degree of genetic conservation for this virus type. An explanation of this could be that Ebola viruses may have coevolved with their natural host reservoirs and do not change a lot in the wild.
Reference
Biology of Negative Strand RNA Viruses: The Power of Reverse Genetics; Y. Kawaoka (Ed.). © Springer-Verlag Berlin Heidelberg 2004.
Ebihara H, Takada A, Kobasa D, Jones S, Neumann G, et al. (2006) Molecular determinants of Ebola virus virulence in mice. PLoS Pathog 2(7): e73. DOI: 10.1371/ journal.ppat.0020073.
MOLECULAR BASIS OF VIRUS EVOLUTION; Edited by ADRIAN J. GIBBS, CHARLES H. CALISHER, and FERNANDO GARCIA-ARENAL, © Cambridge University Press 1995.
http://www.ncbi.nlm.nih.gov/pubmed/?term=ebola+virus+review
The Zaire Ebola Virus Genome and Proteome
Zaire ebolavirus isolate Ebola virus H.sapiens-tc/COD/1976/Yambuku-Mayinga, complete genome. NCBI Reference Sequence: NC_002549.1.
Source
![]()
![]()
![]()
LOCUS NC_002549 18959 bp cRNA linear VRL 27-AUG-2014
DEFINITION Zaire ebolavirus isolate Ebola virus
H.sapiens-tc/COD/1976/Yambuku-Mayinga, complete genome.
ACCESSION NC_002549
VERSION NC_002549.1 GI:10313991
DBLINK BioProject: PRJNA14703
KEYWORDS RefSeq.
SOURCE Zaire ebolavirus (ZEBOV)
ORGANISM Zaire ebolavirus
Viruses; ssRNA negative-strand viruses; Mononegavirales;
Filoviridae; Ebolavirus.
REFERENCE 1 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Volchkova,V.A., Chepurnov,A.A., Blinov,V.M.,
Dolnik,O., Netesov,S.V. and Feldmann,H.
TITLE Characterization of the L gene and 5' trailer region of Ebola virus
JOURNAL J. Gen. Virol. 80 (Pt 2), 355-362 (1999)
PUBMED 10073695
REFERENCE 2 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Volchkova,V.A., Slenczka,W., Klenk,H.D. and
Feldmann,H.
TITLE Release of viral glycoproteins during Ebola virus infection
JOURNAL Virology 245 (1), 110-119 (1998)
PUBMED 9614872
REFERENCE 3 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Feldmann,H., Volchkova,V.A. and Klenk,H.D.
TITLE Processing of the Ebola virus glycoprotein by the proprotein
convertase furin
JOURNAL Proc. Natl. Acad. Sci. U.S.A. 95 (10), 5762-5767 (1998)
PUBMED 9576958
REFERENCE 4 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Becker,S., Volchkova,V.A., Ternovoj,V.A.,
Kotov,A.N., Netesov,S.V. and Klenk,H.D.
TITLE GP mRNA of Ebola virus is edited by the Ebola virus polymerase and
by T7 and vaccinia virus polymerases
JOURNAL Virology 214 (2), 421-430 (1995)
PUBMED 8553543
REFERENCE 5 (bases 1 to 18959)
AUTHORS Bukreyev,A.A., Volchkov,V.E., Blinov,V.M. and Netesov,S.V.
TITLE The VP35 and VP40 proteins of filoviruses. Homology between Marburg
and Ebola viruses
JOURNAL FEBS Lett. 322 (1), 41-46 (1993)
PUBMED 8482365
REFERENCE 6 (bases 1 to 18959)
CONSRTM NCBI Genome Project
TITLE Direct Submission
JOURNAL Submitted (27-SEP-2000) National Center for Biotechnology
Information, NIH, Bethesda, MD 20894, USA
REFERENCE 7 (bases 1 to 18959)
AUTHORS Volchkov,V.E.
TITLE Direct Submission
JOURNAL Submitted (02-JUN-2000) Institute of Virology, Philipps-University
Marburg, Robert-Koch-Str. 17, Marburg 35037, Germany
REMARK Sequence update by submitter
REFERENCE 8 (bases 1 to 18959)
AUTHORS Volchkov,V.E.
TITLE Direct Submission
JOURNAL Submitted (20-AUG-1998) Institute of Virology, Philipps-University
Marburg, Robert-Koch-Str. 17, Marburg 35037, Germany
COMMENT PROVISIONAL REFSEQ: This record has not yet been subject to final
NCBI review. The reference sequence is identical to AF086833.
COMPLETENESS: full length.
FEATURES Location/Qualifiers
source 1..18959
/organism="Zaire ebolavirus"
/mol_type="viral cRNA"
/isolate="Ebola virus
H.sapiens-tc/COD/1976/Yambuku-Mayinga"
/db_xref="taxon:186538"
5'UTR 1..55
/note="putative leader region"
/citation=[1]
/function="regulation or initiation of RNA replication"
gene 56..3026
/gene="NP"
/locus_tag="ZEBOVgp1"
/db_xref="GeneID:911830"
mRNA 56..3026
/gene="NP"
/locus_tag="ZEBOVgp1"
/product="nucleoprotein"
/db_xref="GeneID:911830"
misc_signal 56..67
/gene="NP"
/locus_tag="ZEBOVgp1"
/note="putative; transcription start signal"
/citation=[1]
CDS 470..2689
/gene="NP"
/locus_tag="ZEBOVgp1"
/function="encapsidation of genomic RNA"
/codon_start=1
/product="nucleoprotein"
/protein_id="NP_066243.1"
/db_xref="GI:10314000"
/db_xref="GeneID:911830"
/translation="MDSRPQKIWMAPSLTESDMDYHKILTAGLSVQQGIVRQRVIPVY
QVNNLEEICQLIIQAFEAGVDFQESADSFLLMLCLHHAYQGDYKLFLESGAVKYLEGH
GFRFEVKKRDGVKRLEELLPAVSSGKNIKRTLAAMPEEETTEANAGQFLSFASLFLPK
LVVGEKACLEKVQRQIQVHAEQGLIQYPTAWQSVGHMMVIFRLMRTNFLIKFLLIHQG
MHMVAGHDANDAVISNSVAQARFSGLLIVKTVLDHILQKTERGVRLHPLARTAKVKNE
VNSFKAALSSLAKHGEYAPFARLLNLSGVNNLEHGLFPQLSAIALGVATAHGSTLAGV
NVGEQYQQLREAATEAEKQLQQYAESRELDHLGLDDQEKKILMNFHQKKNEISFQQTN
AMVTLRKERLAKLTEAITAASLPKTSGHYDDDDDIPFPGPINDDDNPGHQDDDPTDSQ
DTTIPDVVVDPDDGSYGEYQSYSENGMNAPDDLVLFDLDEDDEDTKPVPNRSTKGGQQ
KNSQKGQHIEGRQTQSRPIQNVPGPHRTIHHASAPLTDNDRRNEPSGSTSPRMLTPIN
EEADPLDDADDETSSLPPLESDDEEQDRDGTSNRTPTVAPPAPVYRDHSEKKELPQDE
QQDQDHTQEARNQDSDNTQSEHSFEEMYRHILRSQGPFDAVLYYHMMKDEPVVFSTSD
GKEYTYPDSLEEEYPPWLTEKEAMNEENRFVTLDGQQFYWPVMNHKNKFMAILQHHQ"
misc_feature 524..2671
/gene="NP"
/locus_tag="ZEBOVgp1"
/note="Ebola nucleoprotein; Region: Ebola_NP; pfam05505"
/db_xref="CDD:147601"
polyA_signal 3015..3026
/gene="NP"
/locus_tag="ZEBOVgp1"
misc_feature 3027..3031
/note="intergenic region"
gene 3032..4407
/gene="VP35"
/locus_tag="ZEBOVgp2"
/db_xref="GeneID:911827"
mRNA 3032..4407
/gene="VP35"
/locus_tag="ZEBOVgp2"
/product="VP35"
/citation=[5]
/db_xref="GeneID:911827"
misc_signal 3032..3043
/gene="VP35"
/locus_tag="ZEBOVgp2"
/note="putative; transcription start signal"
/citation=[5]
CDS 3129..4151
/gene="VP35"
/locus_tag="ZEBOVgp2"
/function="polymerase complex protein"
/citation=[5]
/codon_start=1
/product="polymerase complex protein"
/protein_id="NP_066244.1"
/db_xref="GI:10313992"
/db_xref="GeneID:911827"
/translation="MTTRTKGRGHTAATTQNDRMPGPELSGWISEQLMTGRIPVSDIF
CDIENNPGLCYASQMQQTKPNPKTRNSQTQTDPICNHSFEEVVQTLASLATVVQQQTI
ASESLEQRITSLENGLKPVYDMAKTISSLNRVCAEMVAKYDLLVMTTGRATATAAATE
AYWAEHGQPPPGPSLYEESAIRGKIESRDETVPQSVREAFNNLNSTTSLTEENFGKPD
ISAKDLRNIMYDHLPGFGTAFHQLVQVICKLGKDSNSLDIIHAEFQASLAEGDSPQCA
LIQITKRVPIFQDAAPPVIHIRSRGDIPRACQKSLRPVPPSPKIDRGWVCVFQLQDGK
TLGLKI"
misc_feature 3186..4148
/gene="VP35"
/locus_tag="ZEBOVgp2"
/note="Filoviridae VP35; Region: Filo_VP35; pfam02097"
/db_xref="CDD:145320"
gene 4390..5894
/gene="VP40"
/locus_tag="ZEBOVgp3"
/db_xref="GeneID:911825"
mRNA 4390..5894
/gene="VP40"
/locus_tag="ZEBOVgp3"
/product="VP40"
/citation=[5]
/db_xref="GeneID:911825"
misc_signal 4390..4401
/gene="VP40"
/locus_tag="ZEBOVgp3"
/note="transcription start signal"
/citation=[5]
polyA_signal 4397..4407
/gene="VP35"
/locus_tag="ZEBOVgp2"
/citation=[5]
CDS 4479..5459
/gene="VP40"
/locus_tag="ZEBOVgp3"
/citation=[5]
/codon_start=1
/product="matrix protein"
/protein_id="NP_066245.1"
/db_xref="GI:10313993"
/db_xref="GeneID:911825"
/translation="MRRVILPTAPPEYMEAIYPVRSNSTIARGGNSNTGFLTPESVNG
DTPSNPLRPIADDTIDHASHTPGSVSSAFILEAMVNVISGPKVLMKQIPIWLPLGVAD
QKTYSFDSTTAAIMLASYTITHFGKATNPLVRVNRLGPGIPDHPLRLLRIGNQAFLQE
FVLPPVQLPQYFTFDLTALKLITQPLPAATWTDDTPTGSNGALRPGISFHPKLRPILL
PNKSGKKGNSADLTSPEKIQAIMTSLQDFKIVPIDPTKNIMGIEVPETLVHKLTGKKV
TSKNGQPIIPVLLPKYIGLDPVAPGDLTMVITQDCDTCHSPASLPAVIEK"
misc_feature 4479..5363
/gene="VP40"
/locus_tag="ZEBOVgp3"
/note="Matrix protein VP40; Region: VP40; pfam07447"
/db_xref="CDD:116068"
polyA_signal 5883..5894
/gene="VP40"
/locus_tag="ZEBOVgp3"
/citation=[5]
misc_feature 5895..5899
/note="intergenic region"
gene 5900..8305
/gene="GP"
/locus_tag="ZEBOVgp4"
/db_xref="GeneID:911829"
mRNA 5900..8305
/gene="GP"
/locus_tag="ZEBOVgp4"
/product="sGP"
/note="unedited mRNA"
/citation=[4]
/db_xref="GeneID:911829"
misc_signal 5900..5911
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="putative; transcription start signal"
/citation=[4]
CDS join(6039..6923,6923..8068)
/gene="GP"
/locus_tag="ZEBOVgp4"
/function="receptor binding and fusion"
/artificial_location="low-quality sequence region"
/note="virion spike glycoprotein precursor; an addition A
residue is inserted during transcription; encodes two
disulfide linked subunits GP1 and GP2"
/citation=[2]
/citation=[3]
/citation=[4]
/codon_start=1
/product="spike glycoprotein"
/protein_id="NP_066246.1"
/db_xref="GI:10313995"
/db_xref="GeneID:911829"
/translation="MGVTGILQLPRDRFKRTSFFLWVIILFQRTFSIPLGVIHNSTLQ
VSDVDKLVCRDKLSSTNQLRSVGLNLEGNGVATDVPSATKRWGFRSGVPPKVVNYEAG
EWAENCYNLEIKKPDGSECLPAAPDGIRGFPRCRYVHKVSGTGPCAGDFAFHKEGAFF
LYDRLASTVIYRGTTFAEGVVAFLILPQAKKDFFSSHPLREPVNATEDPSSGYYSTTI
RYQATGFGTNETEYLFEVDNLTYVQLESRFTPQFLLQLNETIYTSGKRSNTTGKLIWK
VNPEIDTTIGEWAFWETKKNLTRKIRSEELSFTVVSNGAKNISGQSPARTSSDPGTNT
TTEDHKIMASENSSAMVQVHSQGREAAVSHLTTLATISTSPQSLTTKPGPDNSTHNTP
VYKLDISEATQVEQHHRRTDNDSTASDTPSATTAAGPPKAENTNTSKSTDFLDPATTT
SPQNHSETAGNNNTHHQDTGEESASSGKLGLITNTIAGVAGLITGGRRTRREAIVNAQ
PKCNPNLHYWTTQDEGAAIGLAWIPYFGPAAEGIYIEGLMHNQDGLICGLRQLANETT
QALQLFLRATTELRTFSILNRKAIDFLLQRWGGTCHILGPDCCIEPHDWTKNITDKID
QIIHDFVDKTLPDQGDNDNWWTGWRQWIPAGIGVTGVIIAVIALFCICKFVF"
misc_feature 7529..7540
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="encodes the glycoprotein cleavage site, precursor
GP is cleaved by subtilisin-like cellular protease furin
into subunits GP1 and GP2 that are linked by a disulfide
bond"
/citation=[3]
misc_feature 7793..7870
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="immunosuppressive motif; other site"
misc_feature 7988..8053
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="transmembrane anchor; transmembrane region"
misc_feature 7706..7924
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="heptad repeat 1-heptad repeat 2 region of the
transmembrane subunit of Filoviridae viruses, Ebola virus
and Marburg virus, and related domains; Region:
Ebola-like_HR1-HR2; cd09850"
/db_xref="CDD:197367"
misc_feature join(6081..6923,6923..7153)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Filovirus glycoprotein; Region: Filo_glycop;
pfam01611"
/db_xref="CDD:110602"
misc_feature 7706..7732
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1A; other site"
/db_xref="CDD:197367"
misc_feature 7733..7762
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1B; other site"
/db_xref="CDD:197367"
misc_feature 7763..7783
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1C; other site"
/db_xref="CDD:197367"
misc_feature 7784..7831
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1D; other site"
/db_xref="CDD:197367"
misc_feature 7787..7837
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="immunosuppressive region; other site"
/db_xref="CDD:197367"
misc_feature order(7838..7858,7859..7861)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="CX(6,7)C motif; other site"
/db_xref="CDD:197367"
misc_feature 7886..7924
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR2; other site"
/db_xref="CDD:197367"
misc_feature order(7784..7786,7793..7795)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Cl binding site [ion binding]; other site"
/db_xref="CDD:197367"
misc_feature order(7706..7714,7718..7723,7727..7732,7736..7744,
7748..7756,7760..7765,7769..7777,7781..7807,7811..7819,
7823..7828,7844..7849,7856..7858,7865..7876,7880..7882,
7889..7894,7901..7903,7910..7915,7922..7924)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="homotrimer interface [polypeptide binding]; other
site"
/db_xref="CDD:197367"
misc_feature order(7706..7714,7718..7726,7730..7735,7739..7747,
7754..7768,7772..7783,7787..7792,7796..7804,7808..7813,
7817..7819)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1-GP1 interface [polypeptide binding]; other
site"
/db_xref="CDD:197367"
CDS 6039..7133
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="sGP, small non-structural, secreted glycoprotein;
sGP secreted as a anti-parallel oriented homodimer"
/citation=[4]
/codon_start=1
/product="small secreted glycoprotein"
/protein_id="NP_066247.1"
/db_xref="GI:10313994"
/db_xref="GeneID:911829"
/translation="MGVTGILQLPRDRFKRTSFFLWVIILFQRTFSIPLGVIHNSTLQ
VSDVDKLVCRDKLSSTNQLRSVGLNLEGNGVATDVPSATKRWGFRSGVPPKVVNYEAG
EWAENCYNLEIKKPDGSECLPAAPDGIRGFPRCRYVHKVSGTGPCAGDFAFHKEGAFF
LYDRLASTVIYRGTTFAEGVVAFLILPQAKKDFFSSHPLREPVNATEDPSSGYYSTTI
RYQATGFGTNETEYLFEVDNLTYVQLESRFTPQFLLQLNETIYTSGKRSNTTGKLIWK
VNPEIDTTIGEWAFWETKKTSLEKFAVKSCLSQLYQTEPKTSVVRVRRELLPTQGPTQ
QLKTTKSWLQKIPLQWFKCTVKEGKLQCRI"
misc_feature 6081..7130
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Filovirus glycoprotein; Region: Filo_glycop;
pfam01611"
/db_xref="CDD:110602"
CDS join(6039..6922,6924..6933)
/gene="GP"
/locus_tag="ZEBOVgp4"
/artificial_location="low-quality sequence region"
/note="ssGP; second non-structural secreted glycoprotein;
secreted in a monomeric form; one A residue is deleted or
two additional A residues are inserted at the editing site
during transcription of the GP gene"
/citation=[4]
/codon_start=1
/product="second secreted glycoprotein"
/protein_id="NP_066248.1"
/db_xref="GI:10313996"
/db_xref="GeneID:911829"
/translation="MGVTGILQLPRDRFKRTSFFLWVIILFQRTFSIPLGVIHNSTLQ
VSDVDKLVCRDKLSSTNQLRSVGLNLEGNGVATDVPSATKRWGFRSGVPPKVVNYEAG
EWAENCYNLEIKKPDGSECLPAAPDGIRGFPRCRYVHKVSGTGPCAGDFAFHKEGAFF
LYDRLASTVIYRGTTFAEGVVAFLILPQAKKDFFSSHPLREPVNATEDPSSGYYSTTI
RYQATGFGTNETEYLFEVDNLTYVQLESRFTPQFLLQLNETIYTSGKRSNTTGKLIWK
VNPEIDTTIGEWAFWETKKPH"
misc_feature join(6081..6922,6924..>6924)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Filovirus glycoprotein; Region: Filo_glycop;
pfam01611"
/db_xref="CDD:110602"
misc_signal 6918..6924
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="additional A residues are inserted or deleted
during transcription of the GP gene by the viral
polymerase"
/citation=[4]
/function="RNA editing"
gene 8288..9740
/gene="VP30"
/locus_tag="ZEBOVgp5"
/db_xref="GeneID:911826"
mRNA 8288..9740
/gene="VP30"
/locus_tag="ZEBOVgp5"
/product="VP30"
/db_xref="GeneID:911826"
misc_signal 8288..8299
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="putative; transcription start signal"
polyA_signal 8295..8305
/gene="GP"
/locus_tag="ZEBOVgp4"
/citation=[4]
CDS 8509..9375
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="polymerase complex protein"
/codon_start=1
/product="minor nucleoprotein"
/protein_id="NP_066249.1"
/db_xref="GI:10313997"
/db_xref="GeneID:911826"
/translation="MEASYERGRPRAARQHSRDGHDHHVRARSSSRENYRGEYRQSRS
ASQVRVPTVFHKKRVEPLTVPPAPKDICPTLKKGFLCDSSFCKKDHQLESLTDRELLL
LIARKTCGSVEQQLNITAPKDSRLANPTADDFQQEEGPKITLLTLIKTAEHWARQDIR
TIEDSKLRALLTLCAVMTRKFSKSQLSLLCETHLRREGLGQDQAEPVLEVYQRLHSDK
GGSFEAALWQQWDRQSLIMFITAFLNIALQLPCESSAVVVSGLRTLVPQSDNEEASTN
PGTCSWSDEGTP"
misc_feature 8932..9321
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="Ebola virus-specific transcription factor VP30;
Region: Transcript_VP30; pfam11507"
/db_xref="CDD:151944"
polyA_signal 9730..9740
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="putative"
misc_feature 9741..9884
/note="intergenic region"
gene 9885..11518
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="putative"
/db_xref="GeneID:911828"
mRNA 9885..11496
/gene="VP24"
/locus_tag="ZEBOVgp6"
/product="VP24"
/db_xref="GeneID:911828"
misc_signal 9885..9896
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="transcription start signal"
CDS 10345..11100
/gene="VP24"
/locus_tag="ZEBOVgp6"
/codon_start=1
/product="membrane-associated protein"
/protein_id="NP_066250.1"
/db_xref="GI:10313998"
/db_xref="GeneID:911828"
/translation="MAKATGRYNLISPKKDLEKGVVLSDLCNFLVSQTIQGWKVYWAG
IEFDVTHKGMALLHRLKTNDFAPAWSMTRNLFPHLFQNPNSTIESPLWALRVILAAGI
QDQLIDQSLIEPLAGALGLISDWLLTTNTNHFNMRTQRVKEQLSLKMLSLIRSNILKF
INKLDALHVVNYNGLLSSIEIGTQNHTIIITRTNMGFLVELQEPDKSAMNRMKPGPAK
FSLLHESTLKAFTQGSSTRMQSLILEFNSSLAI"
misc_feature 10369..11040
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="Filovirus membrane-associated protein VP24; Region:
Filo_VP24; pfam06389"
/db_xref="CDD:253701"
polyA_signal 11485..11496
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="putative"
misc_feature 11497..11500
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="intergenic region"
gene 11501..18282
/gene="L"
/locus_tag="ZEBOVgp7"
/db_xref="GeneID:911824"
mRNA 11501..18282
/gene="L"
/locus_tag="ZEBOVgp7"
/product="polymerase"
/citation=[1]
/db_xref="GeneID:911824"
misc_signal 11501..11512
/gene="L"
/locus_tag="ZEBOVgp7"
/note="transcription start signal"
/citation=[1]
polyA_signal 11508..11518
/gene="VP24"
/locus_tag="ZEBOVgp6"
CDS 11581..18219
/gene="L"
/locus_tag="ZEBOVgp7"
/function="synthesis of viral RNAs; transcriptional RNA
editing"
/note="polymerase"
/citation=[1]
/codon_start=1
/product="RNA-dependent RNA polymerase"
/protein_id="NP_066251.1"
/db_xref="GI:10313999"
/db_xref="GeneID:911824"
/translation="MATQHTQYPDARLSSPIVLDQCDLVTRACGLYSSYSLNPQLRNC
KLPKHIYRLKYDVTVTKFLSDVPVATLPIDFIVPVLLKALSGNGFCPVEPRCQQFLDE
IIKYTMQDALFLKYYLKNVGAQEDCVDEHFQEKILSSIQGNEFLHQMFFWYDLAILTR
RGRLNRGNSRSTWFVHDDLIDILGYGDYVFWKIPISMLPLNTQGIPHAAMDWYQASVF
KEAVQGHTHIVSVSTADVLIMCKDLITCRFNTTLISKIAEIEDPVCSDYPNFKIVSML
YQSGDYLLSILGSDGYKIIKFLEPLCLAKIQLCSKYTERKGRFLTQMHLAVNHTLEEI
TEMRALKPSQAQKIREFHRTLIRLEMTPQQLCELFSIQKHWGHPVLHSETAIQKVKKH
ATVLKALRPIVIFETYCVFKYSIAKHYFDSQGSWYSVTSDRNLTPGLNSYIKRNQFPP
LPMIKELLWEFYHLDHPPLFSTKIISDLSIFIKDRATAVERTCWDAVFEPNVLGYNPP
HKFSTKRVPEQFLEQENFSIENVLSYAQKLEYLLPQYRNFSFSLKEKELNVGRTFGKL
PYPTRNVQTLCEALLADGLAKAFPSNMMVVTEREQKESLLHQASWHHTSDDFGEHATV
RGSSFVTDLEKYNLAFRYEFTAPFIEYCNRCYGVKNVFNWMHYTIPQCYMHVSDYYNP
PHNLTLENRDNPPEGPSSYRGHMGGIEGLQQKLWTSISCAQISLVEIKTGFKLRSAVM
GDNQCITVLSVFPLETDADEQEQSAEDNAARVAASLAKVTSACGIFLKPDETFVHSGF
IYFGKKQYLNGVQLPQSLKTATRMAPLSDAIFDDLQGTLASIGTAFERSISETRHIFP
CRITAAFHTFFSVRILQYHHLGFNKGFDLGQLTLGKPLDFGTISLALAVPQVLGGLSF
LNPEKCFYRNLGDPVTSGLFQLKTYLRMIEMDDLFLPLIAKNPGNCTAIDFVLNPSGL
NVPGSQDLTSFLRQIVRRTITLSAKNKLINTLFHASADFEDEMVCKWLLSSTPVMSRF
AADIFSRTPSGKRLQILGYLEGTRTLLASKIINNNTETPVLDRLRKITLQRWSLWFSY
LDHCDNILAEALTQITCTVDLAQILREYSWAHILEGRPLIGATLPCMIEQFKVFWLKP
YEQCPQCSNAKQPGGKPFVSVAVKKHIVSAWPNASRISWTIGDGIPYIGSRTEDKIGQ
PAIKPKCPSAALREAIELASRLTWVTQGSSNSDLLIKPFLEARVNLSVQEILQMTPSH
YSGNIVHRYNDQYSPHSFMANRMSNSATRLIVSTNTLGEFSGGGQSARDSNIIFQNVI
NYAVALFDIKFRNTEATDIQYNRAHLHLTKCCTREVPAQYLTYTSTLDLDLTRYRENE
LIYDSNPLKGGLNCNISFDNPFFQGKRLNIIEDDLIRLPHLSGWELAKTIMQSIISDS
NNSSTDPISSGETRSFTTHFLTYPKIGLLYSFGAFVSYYLGNTILRTKKLTLDNFLYY
LTTQIHNLPHRSLRILKPTFKHASVMSRLMSIDPHFSIYIGGAAGDRGLSDAARLFLR
TSISSFLTFVKEWIINRGTIVPLWIVYPLEGQNPTPVNNFLYQIVELLVHDSSRQQAF
KTTISDHVHPHDNLVYTCKSTASNFFHASLAYWRSRHRNSNRKYLARDSSTGSSTNNS
DGHIERSQEQTTRDPHDGTERNLVLQMSHEIKRTTIPQENTHQGPSFQSFLSDSACGT
ANPKLNFDRSRHNVKFQDHNSASKREGHQIISHRLVLPFFTLSQGTRQLTSSNESQTQ
DEISKYLRQLRSVIDTTVYCRFTGIVSSMHYKLDEVLWEIESFKSAVTLAEGEGAGAL
LLIQKYQVKTLFFNTLATESSIESEIVSGMTTPRMLLPVMSKFHNDQIEIILNNSASQ
ITDITNPTWFKDQRARLPKQVEVITMDAETTENINRSKLYEAVYKLILHHIDPSVLKA
VVLKVFLSDTEGMLWLNDNLAPFFATGYLIKPITSSARSSEWYLCLTNFLSTTRKMPH
QNHLSCKQVILTALQLQIQRSPYWLSHLTQYADCELHLSYIRLGFPSLEKVLYHRYNL
VDSKRGPLVSITQHLAHLRAEIRELTNDYNQQRQSRTQTYHFIRTAKGRITKLVNDYL
KFFLIVQALKHNGTWQAEFKKLPELISVCNRFYHIRDCNCEERFLVQTLYLHRMQDSE
VKLIERLTGLLSLFPDGLYRFD"
misc_feature 11608..14853
/gene="L"
/locus_tag="ZEBOVgp7"
/note="Mononegavirales RNA dependent RNA polymerase;
Region: Mononeg_RNA_pol; pfam00946"
/db_xref="CDD:250248"
misc_feature 15223..18192
/gene="L"
/locus_tag="ZEBOVgp7"
/note="mRNA capping enzyme, paramyxovirus family; Region:
paramyx_RNAcap; TIGR04198"
/db_xref="CDD:234496"
polyA_signal 18272..18282
/gene="L"
/locus_tag="ZEBOVgp7"
/citation=[1]
3'UTR 18283..18959
/note="putative trailer region"
/citation=[1]
/function="regulation or initiation of RNA replication"
ORIGIN
1 cggacacaca aaaagaaaga agaattttta ggatcttttg tgtgcgaata actatgagga
61 agattaataa ttttcctctc attgaaattt atatcggaat ttaaattgaa attgttactg
121 taatcacacc tggtttgttt cagagccaca tcacaaagat agagaacaac ctaggtctcc
181 gaagggagca agggcatcag tgtgctcagt tgaaaatccc ttgtcaacac ctaggtctta
241 tcacatcaca agttccacct cagactctgc agggtgatcc aacaacctta atagaaacat
301 tattgttaaa ggacagcatt agttcacagt caaacaagca agattgagaa ttaaccttgg
361 ttttgaactt gaacacttag gggattgaag attcaacaac cctaaagctt ggggtaaaac
421 attggaaata gttaaaagac aaattgctcg gaatcacaaa attccgagta tggattctcg
481 tcctcagaaa atctggatgg cgccgagtct cactgaatct gacatggatt accacaagat
541 cttgacagca ggtctgtccg ttcaacaggg gattgttcgg caaagagtca tcccagtgta
601 tcaagtaaac aatcttgaag aaatttgcca acttatcata caggcctttg aagcaggtgt
661 tgattttcaa gagagtgcgg acagtttcct tctcatgctt tgtcttcatc atgcgtacca
721 gggagattac aaacttttct tggaaagtgg cgcagtcaag tatttggaag ggcacgggtt
781 ccgttttgaa gtcaagaagc gtgatggagt gaagcgcctt gaggaattgc tgccagcagt
841 atctagtgga aaaaacatta agagaacact tgctgccatg ccggaagagg agacaactga
901 agctaatgcc ggtcagtttc tctcctttgc aagtctattc cttccgaaat tggtagtagg
961 agaaaaggct tgccttgaga aggttcaaag gcaaattcaa gtacatgcag agcaaggact
1021 gatacaatat ccaacagctt ggcaatcagt aggacacatg atggtgattt tccgtttgat
1081 gcgaacaaat tttctgatca aatttctcct aatacaccaa gggatgcaca tggttgccgg
1141 gcatgatgcc aacgatgctg tgatttcaaa ttcagtggct caagctcgtt tttcaggctt
1201 attgattgtc aaaacagtac ttgatcatat cctacaaaag acagaacgag gagttcgtct
1261 ccatcctctt gcaaggaccg ccaaggtaaa aaatgaggtg aactccttta aggctgcact
1321 cagctccctg gccaagcatg gagagtatgc tcctttcgcc cgacttttga acctttctgg
1381 agtaaataat cttgagcatg gtcttttccc tcaactatcg gcaattgcac tcggagtcgc
1441 cacagcacac gggagtaccc tcgcaggagt aaatgttgga gaacagtatc aacaactcag
1501 agaggctgcc actgaggctg agaagcaact ccaacaatat gcagagtctc gcgaacttga
1561 ccatcttgga cttgatgatc aggaaaagaa aattcttatg aacttccatc agaaaaagaa
1621 cgaaatcagc ttccagcaaa caaacgctat ggtaactcta agaaaagagc gcctggccaa
1681 gctgacagaa gctatcactg ctgcgtcact gcccaaaaca agtggacatt acgatgatga
1741 tgacgacatt ccctttccag gacccatcaa tgatgacgac aatcctggcc atcaagatga
1801 tgatccgact gactcacagg atacgaccat tcccgatgtg gtggttgatc ccgatgatgg
1861 aagctacggc gaataccaga gttactcgga aaacggcatg aatgcaccag atgacttggt
1921 cctattcgat ctagacgagg acgacgagga cactaagcca gtgcctaata gatcgaccaa
1981 gggtggacaa cagaagaaca gtcaaaaggg ccagcatata gagggcagac agacacaatc
2041 caggccaatt caaaatgtcc caggccctca cagaacaatc caccacgcca gtgcgccact
2101 cacggacaat gacagaagaa atgaaccctc cggctcaacc agccctcgca tgctgacacc
2161 aattaacgaa gaggcagacc cactggacga tgccgacgac gagacgtcta gccttccgcc
2221 cttggagtca gatgatgaag agcaggacag ggacggaact tccaaccgca cacccactgt
2281 cgccccaccg gctcccgtat acagagatca ctctgaaaag aaagaactcc cgcaagacga
2341 gcaacaagat caggaccaca ctcaagaggc caggaaccag gacagtgaca acacccagtc
2401 agaacactct tttgaggaga tgtatcgcca cattctaaga tcacaggggc catttgatgc
2461 tgttttgtat tatcatatga tgaaggatga gcctgtagtt ttcagtacca gtgatggcaa
2521 agagtacacg tatccagact cccttgaaga ggaatatcca ccatggctca ctgaaaaaga
2581 ggctatgaat gaagagaata gatttgttac attggatggt caacaatttt attggccggt
2641 gatgaatcac aagaataaat tcatggcaat cctgcaacat catcagtgaa tgagcatgga
2701 acaatgggat gattcaaccg acaaatagct aacattaagt agtcaaggaa cgaaaacagg
2761 aagaattttt gatgtctaag gtgtgaatta ttatcacaat aaaagtgatt cttatttttg
2821 aatttaaagc tagcttatta ttactagccg tttttcaaag ttcaatttga gtcttaatgc
2881 aaataggcgt taagccacag ttatagccat aattgtaact caatattcta actagcgatt
2941 tatctaaatt aaattacatt atgcttttat aacttaccta ctagcctgcc caacatttac
3001 acgatcgttt tataattaag aaaaaactaa tgatgaagat taaaaccttc atcatcctta
3061 cgtcaattga attctctagc actcgaagct tattgtcttc aatgtaaaag aaaagctggt
3121 ctaacaagat gacaactaga acaaagggca ggggccatac tgcggccacg actcaaaacg
3181 acagaatgcc aggccctgag ctttcgggct ggatctctga gcagctaatg accggaagaa
3241 ttcctgtaag cgacatcttc tgtgatattg agaacaatcc aggattatgc tacgcatccc
3301 aaatgcaaca aacgaagcca aacccgaaga cgcgcaacag tcaaacccaa acggacccaa
3361 tttgcaatca tagttttgag gaggtagtac aaacattggc ttcattggct actgttgtgc
3421 aacaacaaac catcgcatca gaatcattag aacaacgcat tacgagtctt gagaatggtc
3481 taaagccagt ttatgatatg gcaaaaacaa tctcctcatt gaacagggtt tgtgctgaga
3541 tggttgcaaa atatgatctt ctggtgatga caaccggtcg ggcaacagca accgctgcgg
3601 caactgaggc ttattgggcc gaacatggtc aaccaccacc tggaccatca ctttatgaag
3661 aaagtgcgat tcggggtaag attgaatcta gagatgagac cgtccctcaa agtgttaggg
3721 aggcattcaa caatctaaac agtaccactt cactaactga ggaaaatttt gggaaacctg
3781 acatttcggc aaaggatttg agaaacatta tgtatgatca cttgcctggt tttggaactg
3841 ctttccacca attagtacaa gtgatttgta aattgggaaa agatagcaac tcattggaca
3901 tcattcatgc tgagttccag gccagcctgg ctgaaggaga ctctcctcaa tgtgccctaa
3961 ttcaaattac aaaaagagtt ccaatcttcc aagatgctgc tccacctgtc atccacatcc
4021 gctctcgagg tgacattccc cgagcttgcc agaaaagctt gcgtccagtc ccaccatcgc
4081 ccaagattga tcgaggttgg gtatgtgttt ttcagcttca agatggtaaa acacttggac
4141 tcaaaatttg agccaatctc ccttccctcc gaaagaggcg aataatagca gaggcttcaa
4201 ctgctgaact atagggtacg ttacattaat gatacacttg tgagtatcag ccctggataa
4261 tataagtcaa ttaaacgacc aagataaaat tgttcatatc tcgctagcag cttaaaatat
4321 aaatgtaata ggagctatat ctctgacagt attataatca attgttatta agtaacccaa
4381 accaaaagtg atgaagatta agaaaaacct acctcggctg agagagtgtt ttttcattaa
4441 ccttcatctt gtaaacgttg agcaaaattg ttaaaaatat gaggcgggtt atattgccta
4501 ctgctcctcc tgaatatatg gaggccatat accctgtcag gtcaaattca acaattgcta
4561 gaggtggcaa cagcaataca ggcttcctga caccggagtc agtcaatggg gacactccat
4621 cgaatccact caggccaatt gccgatgaca ccatcgacca tgccagccac acaccaggca
4681 gtgtgtcatc agcattcatc cttgaagcta tggtgaatgt catatcgggc cccaaagtgc
4741 taatgaagca aattccaatt tggcttcctc taggtgtcgc tgatcaaaag acctacagct
4801 ttgactcaac tacggccgcc atcatgcttg cttcatacac tatcacccat ttcggcaagg
4861 caaccaatcc acttgtcaga gtcaatcggc tgggtcctgg aatcccggat catcccctca
4921 ggctcctgcg aattggaaac caggctttcc tccaggagtt cgttcttccg ccagtccaac
4981 taccccagta tttcaccttt gatttgacag cactcaaact gatcacccaa ccactgcctg
5041 ctgcaacatg gaccgatgac actccaacag gatcaaatgg agcgttgcgt ccaggaattt
5101 catttcatcc aaaacttcgc cccattcttt tacccaacaa aagtgggaag aaggggaaca
5161 gtgccgatct aacatctccg gagaaaatcc aagcaataat gacttcactc caggacttta
5221 agatcgttcc aattgatcca accaaaaata tcatgggaat cgaagtgcca gaaactctgg
5281 tccacaagct gaccggtaag aaggtgactt ctaaaaatgg acaaccaatc atccctgttc
5341 ttttgccaaa gtacattggg ttggacccgg tggctccagg agacctcacc atggtaatca
5401 cacaggattg tgacacgtgt cattctcctg caagtcttcc agctgtgatt gagaagtaat
5461 tgcaataatt gactcagatc cagttttata gaatcttctc agggatagtg ataacatcta
5521 tttagtaatc cgtccattag aggagacact tttaattgat caatatacta aaggtgcttt
5581 acaccattgt cttttttctc tcctaaatgt agaacttaac aaaagactca taatatactt
5641 gtttttaaag gattgattga tgaaagatca taactaataa cattacaaat aatcctacta
5701 taatcaatac ggtgattcaa atgttaatct ttctcattgc acatactttt tgcccttatc
5761 ctcaaattgc ctgcatgctt acatctgagg atagccagtg tgacttggat tggaaatgtg
5821 gagaaaaaat cgggacccat ttctaggttg ttcacaatcc aagtacagac attgcccttc
5881 taattaagaa aaaatcggcg atgaagatta agccgacagt gagcgtaatc ttcatctctc
5941 ttagattatt tgttttccag agtaggggtc gtcaggtcct tttcaatcgt gtaaccaaaa
6001 taaactccac tagaaggata ttgtggggca acaacacaat gggcgttaca ggaatattgc
6061 agttacctcg tgatcgattc aagaggacat cattctttct ttgggtaatt atccttttcc
6121 aaagaacatt ttccatccca cttggagtca tccacaatag cacattacag gttagtgatg
6181 tcgacaaact agtttgtcgt gacaaactgt catccacaaa tcaattgaga tcagttggac
6241 tgaatctcga agggaatgga gtggcaactg acgtgccatc tgcaactaaa agatggggct
6301 tcaggtccgg tgtcccacca aaggtggtca attatgaagc tggtgaatgg gctgaaaact
6361 gctacaatct tgaaatcaaa aaacctgacg ggagtgagtg tctaccagca gcgccagacg
6421 ggattcgggg cttcccccgg tgccggtatg tgcacaaagt atcaggaacg ggaccgtgtg
6481 ccggagactt tgccttccat aaagagggtg ctttcttcct gtatgatcga cttgcttcca
6541 cagttatcta ccgaggaacg actttcgctg aaggtgtcgt tgcatttctg atactgcccc
6601 aagctaagaa ggacttcttc agctcacacc ccttgagaga gccggtcaat gcaacggagg
6661 acccgtctag tggctactat tctaccacaa ttagatatca ggctaccggt tttggaacca
6721 atgagacaga gtacttgttc gaggttgaca atttgaccta cgtccaactt gaatcaagat
6781 tcacaccaca gtttctgctc cagctgaatg agacaatata tacaagtggg aaaaggagca
6841 ataccacggg aaaactaatt tggaaggtca accccgaaat tgatacaaca atcggggagt
6901 gggccttctg ggaaactaaa aaaacctcac tagaaaaatt cgcagtgaag agttgtcttt
6961 cacagttgta tcaaacggag ccaaaaacat cagtggtcag agtccggcgc gaacttcttc
7021 cgacccaggg accaacacaa caactgaaga ccacaaaatc atggcttcag aaaattcctc
7081 tgcaatggtt caagtgcaca gtcaaggaag ggaagctgca gtgtcgcatc taacaaccct
7141 tgccacaatc tccacgagtc cccaatccct cacaaccaaa ccaggtccgg acaacagcac
7201 ccataataca cccgtgtata aacttgacat ctctgaggca actcaagttg aacaacatca
7261 ccgcagaaca gacaacgaca gcacagcctc cgacactccc tctgccacga ccgcagccgg
7321 acccccaaaa gcagagaaca ccaacacgag caagagcact gacttcctgg accccgccac
7381 cacaacaagt ccccaaaacc acagcgagac cgctggcaac aacaacactc atcaccaaga
7441 taccggagaa gagagtgcca gcagcgggaa gctaggctta attaccaata ctattgctgg
7501 agtcgcagga ctgatcacag gcgggagaag aactcgaaga gaagcaattg tcaatgctca
7561 acccaaatgc aaccctaatt tacattactg gactactcag gatgaaggtg ctgcaatcgg
7621 actggcctgg ataccatatt tcgggccagc agccgaggga atttacatag aggggctaat
7681 gcacaatcaa gatggtttaa tctgtgggtt gagacagctg gccaacgaga cgactcaagc
7741 tcttcaactg ttcctgagag ccacaactga gctacgcacc ttttcaatcc tcaaccgtaa
7801 ggcaattgat ttcttgctgc agcgatgggg cggcacatgc cacattctgg gaccggactg
7861 ctgtatcgaa ccacatgatt ggaccaagaa cataacagac aaaattgatc agattattca
7921 tgattttgtt gataaaaccc ttccggacca gggggacaat gacaattggt ggacaggatg
7981 gagacaatgg ataccggcag gtattggagt tacaggcgtt ataattgcag ttatcgcttt
8041 attctgtata tgcaaatttg tcttttagtt tttcttcaga ttgcttcatg gaaaagctca
8101 gcctcaaatc aatgaaacca ggatttaatt atatggatta cttgaatcta agattacttg
8161 acaaatgata atataataca ctggagcttt aaacatagcc aatgtgattc taactccttt
8221 aaactcacag ttaatcataa acaaggtttg acatcaatct agttatctct ttgagaatga
8281 taaacttgat gaagattaag aaaaaggtaa tctttcgatt atctttaatc ttcatccttg
8341 attctacaat catgacagtt gtctttagtg acaagggaaa gaagcctttt tattaagttg
8401 taataatcag atctgcgaac cggtagagtt tagttgcaac ctaacacaca taaagcattg
8461 gtcaaaaagt caatagaaat ttaaacagtg agtggagaca acttttaaat ggaagcttca
8521 tatgagagag gacgcccacg agctgccaga cagcattcaa gggatggaca cgaccaccat
8581 gttcgagcac gatcatcatc cagagagaat tatcgaggtg agtaccgtca atcaaggagc
8641 gcctcacaag tgcgcgttcc tactgtattt cataagaaga gagttgaacc attaacagtt
8701 cctccagcac ctaaagacat atgtccgacc ttgaaaaaag gatttttgtg tgacagtagt
8761 ttttgcaaaa aagatcacca gttggagagt ttaactgata gggaattact cctactaatc
8821 gcccgtaaga cttgtggatc agtagaacaa caattaaata taactgcacc caaggactcg
8881 cgcttagcaa atccaacggc tgatgatttc cagcaagagg aaggtccaaa aattaccttg
8941 ttgacactga tcaagacggc agaacactgg gcgagacaag acatcagaac catagaggat
9001 tcaaaattaa gagcattgtt gactctatgt gctgtgatga cgaggaaatt ctcaaaatcc
9061 cagctgagtc ttttatgtga gacacaccta aggcgcgagg ggcttgggca agatcaggca
9121 gaacccgttc tcgaagtata tcaacgatta cacagtgata aaggaggcag ttttgaagct
9181 gcactatggc aacaatggga ccgacaatcc ctaattatgt ttatcactgc attcttgaat
9241 attgctctcc agttaccgtg tgaaagttct gctgtcgttg tttcagggtt aagaacattg
9301 gttcctcaat cagataatga ggaagcttca accaacccgg ggacatgctc atggtctgat
9361 gagggtaccc cttaataagg ctgactaaaa cactatataa ccttctactt gatcacaata
9421 ctccgtatac ctatcatcat atatttaatc aagacgatat cctttaaaac ttattcagta
9481 ctataatcac tctcgtttca aattaataag atgtgcatga ttgccctaat atatgaagag
9541 gtatgataca accctaacag tgatcaaaga aaatcataat ctcgtatcgc tcgtaatata
9601 acctgccaag catacctctt gcacaaagtg attcttgtac acaaataatg ttttactcta
9661 caggaggtag caacgatcca tcccatcaaa aaataagtat ttcatgactt actaatgatc
9721 tcttaaaata ttaagaaaaa ctgacggaac ataaattctt tatgcttcaa gctgtggagg
9781 aggtgtttgg tattggctat tgttatatta caatcaataa caagcttgta aaaatattgt
9841 tcttgtttca agaggtagat tgtgaccgga aatgctaaac taatgatgaa gattaatgcg
9901 gaggtctgat aagaataaac cttattattc agattaggcc ccaagaggca ttcttcatct
9961 ccttttagca aagtactatt tcagggtagt ccaattagtg gcacgtcttt tagctgtata
10021 tcagtcgccc ctgagatacg ccacaaaagt gtctctaagc taaattggtc tgtacacatc
10081 ccatacattg tattaggggc aataatatct aattgaactt agccgtttaa aatttagtgc
10141 ataaatctgg gctaacacca ccaggtcaac tccattggct gaaaagaagc ttacctacaa
10201 cgaacatcac tttgagcgcc ctcacaatta aaaaatagga acgtcgttcc aacaatcgag
10261 cgcaaggttt caaggttgaa ctgagagtgt ctagacaaca aaatattgat actccagaca
10321 ccaagcaaga cctgagaaaa aaccatggct aaagctacgg gacgatacaa tctaatatcg
10381 cccaaaaagg acctggagaa aggggttgtc ttaagcgacc tctgtaactt cttagttagc
10441 caaactattc aggggtggaa ggtttattgg gctggtattg agtttgatgt gactcacaaa
10501 ggaatggccc tattgcatag actgaaaact aatgactttg cccctgcatg gtcaatgaca
10561 aggaatctct ttcctcattt atttcaaaat ccgaattcca caattgaatc accgctgtgg
10621 gcattgagag tcatccttgc agcagggata caggaccagc tgattgacca gtctttgatt
10681 gaacccttag caggagccct tggtctgatc tctgattggc tgctaacaac caacactaac
10741 catttcaaca tgcgaacaca acgtgtcaag gaacaattga gcctaaaaat gctgtcgttg
10801 attcgatcca atattctcaa gtttattaac aaattggatg ctctacatgt cgtgaactac
10861 aacggattgt tgagcagtat tgaaattgga actcaaaatc atacaatcat cataactcga
10921 actaacatgg gttttctggt ggagctccaa gaacccgaca aatcggcaat gaaccgcatg
10981 aagcctgggc cggcgaaatt ttccctcctt catgagtcca cactgaaagc atttacacaa
11041 ggatcctcga cacgaatgca aagtttgatt cttgaattta atagctctct tgctatctaa
11101 ctaaggtaga atacttcata ttgagctaac tcatatatgc tgactcaata gttatcttga
11161 catctctgct ttcataatca gatatataag cataataaat aaatactcat atttcttgat
11221 aatttgttta accacagata aatcctcact gtaagccagc ttccaagttg acacccttac
11281 aaaaaccagg actcagaatc cctcaaacaa gagattccaa gacaacatca tagaattgct
11341 ttattatatg aataagcatt ttatcaccag aaatcctata tactaaatgg ttaattgtaa
11401 ctgaacccgc aggtcacatg tgttaggttt cacagattct atatattact aactctatac
11461 tcgtaattaa cattagataa gtagattaag aaaaaagcct gaggaagatt aagaaaaact
11521 gcttattggg tctttccgtg ttttagatga agcagttgaa attcttcctc ttgatattaa
11581 atggctacac aacataccca atacccagac gctaggttat catcaccaat tgtattggac
11641 caatgtgacc tagtcactag agcttgcggg ttatattcat catactccct taatccgcaa
11701 ctacgcaact gtaaactccc gaaacatatc taccgtttga aatacgatgt aactgttacc
11761 aagttcttga gtgatgtacc agtggcgaca ttgcccatag atttcatagt cccagttctt
11821 ctcaaggcac tgtcaggcaa tggattctgt cctgttgagc cgcggtgcca acagttctta
11881 gatgaaatca ttaagtacac aatgcaagat gctctcttct tgaaatatta tctcaaaaat
11941 gtgggtgctc aagaagactg tgttgatgaa cactttcaag agaaaatctt atcttcaatt
12001 cagggcaatg aatttttaca tcaaatgttt ttctggtatg atctggctat tttaactcga
12061 aggggtagat taaatcgagg aaactctaga tcaacatggt ttgttcatga tgatttaata
12121 gacatcttag gctatgggga ctatgttttt tggaagatcc caatttcaat gttaccactg
12181 aacacacaag gaatccccca tgctgctatg gactggtatc aggcatcagt attcaaagaa
12241 gcggttcaag ggcatacaca cattgtttct gtttctactg ccgacgtctt gataatgtgc
12301 aaagatttaa ttacatgtcg attcaacaca actctaatct caaaaatagc agagattgag
12361 gatccagttt gttctgatta tcccaatttt aagattgtgt ctatgcttta ccagagcgga
12421 gattacttac tctccatatt agggtctgat gggtataaaa ttattaagtt cctcgaacca
12481 ttgtgcttgg ccaaaattca attatgctca aagtacactg agaggaaggg ccgattctta
12541 acacaaatgc atttagctgt aaatcacacc ctagaagaaa ttacagaaat gcgtgcacta
12601 aagccttcac aggctcaaaa gatccgtgaa ttccatagaa cattgataag gctggagatg
12661 acgccacaac aactttgtga gctattttcc attcaaaaac actgggggca tcctgtgcta
12721 catagtgaaa cagcaatcca aaaagttaaa aaacatgcta cggtgctaaa agcattacgc
12781 cctatagtga ttttcgagac atactgtgtt tttaaatata gtattgccaa acattatttt
12841 gatagtcaag gatcttggta cagtgttact tcagatagga atctaacacc gggtcttaat
12901 tcttatatca aaagaaatca attccctccg ttgccaatga ttaaagaact actatgggaa
12961 ttttaccacc ttgaccaccc tccacttttc tcaaccaaaa ttattagtga cttaagtatt
13021 tttataaaag acagagctac cgcagtagaa aggacatgct gggatgcagt attcgagcct
13081 aatgttctag gatataatcc acctcacaaa tttagtacta aacgtgtacc ggaacaattt
13141 ttagagcaag aaaacttttc tattgagaat gttctttcct acgcacaaaa actcgagtat
13201 ctactaccac aatatcggaa cttttctttc tcattgaaag agaaagagtt gaatgtaggt
13261 agaaccttcg gaaaattgcc ttatccgact cgcaatgttc aaacactttg tgaagctctg
13321 ttagctgatg gtcttgctaa agcatttcct agcaatatga tggtagttac ggaacgtgag
13381 caaaaagaaa gcttattgca tcaagcatca tggcaccaca caagtgatga ttttggtgaa
13441 catgccacag ttagagggag tagctttgta actgatttag agaaatacaa tcttgcattt
13501 agatatgagt ttacagcacc ttttatagaa tattgcaacc gttgctatgg tgttaagaat
13561 gtttttaatt ggatgcatta tacaatccca cagtgttata tgcatgtcag tgattattat
13621 aatccaccac ataacctcac actggagaat cgagacaacc cccccgaagg gcctagttca
13681 tacaggggtc atatgggagg gattgaagga ctgcaacaaa aactctggac aagtatttca
13741 tgtgctcaaa tttctttagt tgaaattaag actggtttta agttacgctc agctgtgatg
13801 ggtgacaatc agtgcattac tgttttatca gtcttcccct tagagactga cgcagacgag
13861 caggaacaga gcgccgaaga caatgcagcg agggtggccg ccagcctagc aaaagttaca
13921 agtgcctgtg gaatcttttt aaaacctgat gaaacatttg tacattcagg ttttatctat
13981 tttggaaaaa aacaatattt gaatggggtc caattgcctc agtcccttaa aacggctaca
14041 agaatggcac cattgtctga tgcaattttt gatgatcttc aagggaccct ggctagtata
14101 ggcactgctt ttgagcgatc catctctgag acacgacata tctttccttg caggataacc
14161 gcagctttcc atacgttttt ttcggtgaga atcttgcaat atcatcatct cgggttcaat
14221 aaaggttttg accttggaca gttaacactc ggcaaacctc tggatttcgg aacaatatca
14281 ttggcactag cggtaccgca ggtgcttgga gggttatcct tcttgaatcc tgagaaatgt
14341 ttctaccgga atctaggaga tccagttacc tcaggcttat tccagttaaa aacttatctc
14401 cgaatgattg agatggatga tttattctta cctttaattg cgaagaaccc tgggaactgc
14461 actgccattg actttgtgct aaatcctagc ggattaaatg tccctgggtc gcaagactta
14521 acttcatttc tgcgccagat tgtacgcagg accatcaccc taagtgcgaa aaacaaactt
14581 attaatacct tatttcatgc gtcagctgac ttcgaagacg aaatggtttg taaatggcta
14641 ttatcatcaa ctcctgttat gagtcgtttt gcggccgata tcttttcacg cacgccgagc
14701 gggaagcgat tgcaaattct aggatacctg gaaggaacac gcacattatt agcctctaag
14761 atcatcaaca ataatacaga gacaccggtt ttggacagac tgaggaaaat aacattgcaa
14821 aggtggagcc tatggtttag ttatcttgat cattgtgata atatcctggc ggaggcttta
14881 acccaaataa cttgcacagt tgatttagca cagattctga gggaatattc atgggctcat
14941 attttagagg gaagacctct tattggagcc acactcccat gtatgattga gcaattcaaa
15001 gtgttttggc tgaaacccta cgaacaatgt ccgcagtgtt caaatgcaaa gcaaccaggt
15061 gggaaaccat tcgtgtcagt ggcagtcaag aaacatattg ttagtgcatg gccgaacgca
15121 tcccgaataa gctggactat cggggatgga atcccataca ttggatcaag gacagaagat
15181 aagataggac aacctgctat taaaccaaaa tgtccttccg cagccttaag agaggccatt
15241 gaattggcgt cccgtttaac atgggtaact caaggcagtt cgaacagtga cttgctaata
15301 aaaccatttt tggaagcacg agtaaattta agtgttcaag aaatacttca aatgacccct
15361 tcacattact caggaaatat tgttcacagg tacaacgatc aatacagtcc tcattctttc
15421 atggccaatc gtatgagtaa ttcagcaacg cgattgattg tttctacaaa cactttaggt
15481 gagttttcag gaggtggcca gtctgcacgc gacagcaata ttattttcca gaatgttata
15541 aattatgcag ttgcactgtt cgatattaaa tttagaaaca ctgaggctac agatatccaa
15601 tataatcgtg ctcaccttca tctaactaag tgttgcaccc gggaagtacc agctcagtat
15661 ttaacataca catctacatt ggatttagat ttaacaagat accgagaaaa cgaattgatt
15721 tatgacagta atcctctaaa aggaggactc aattgcaata tctcattcga taatccattt
15781 ttccaaggta aacggctgaa cattatagaa gatgatctta ttcgactgcc tcacttatct
15841 ggatgggagc tagccaagac catcatgcaa tcaattattt cagatagcaa caattcatct
15901 acagacccaa ttagcagtgg agaaacaaga tcattcacta cccatttctt aacttatccc
15961 aagataggac ttctgtacag ttttggggcc tttgtaagtt attatcttgg caatacaatt
16021 cttcggacta agaaattaac acttgacaat tttttatatt acttaactac tcaaattcat
16081 aatctaccac atcgctcatt gcgaatactt aagccaacat tcaaacatgc aagcgttatg
16141 tcacggttaa tgagtattga tcctcatttt tctatttaca taggcggtgc tgcaggtgac
16201 agaggactct cagatgcggc caggttattt ttgagaacgt ccatttcatc ttttcttaca
16261 tttgtaaaag aatggataat taatcgcgga acaattgtcc ctttatggat agtatatccg
16321 ctagagggtc aaaacccaac acctgtgaat aattttctct atcagatcgt agaactgctg
16381 gtgcatgatt catcaagaca acaggctttt aaaactacca taagtgatca tgtacatcct
16441 cacgacaatc ttgtttacac atgtaagagt acagccagca atttcttcca tgcatcattg
16501 gcgtactgga ggagcagaca cagaaacagc aaccgaaaat acttggcaag agactcttca
16561 actggatcaa gcacaaacaa cagtgatggt catattgaga gaagtcaaga acaaaccacc
16621 agagatccac atgatggcac tgaacggaat ctagtcctac aaatgagcca tgaaataaaa
16681 agaacgacaa ttccacaaga aaacacgcac cagggtccgt cgttccagtc ctttctaagt
16741 gactctgctt gtggtacagc aaatccaaaa ctaaatttcg atcgatcgag acacaatgtg
16801 aaatttcagg atcataactc ggcatccaag agggaaggtc atcaaataat ctcacaccgt
16861 ctagtcctac ctttctttac attatctcaa gggacacgcc aattaacgtc atccaatgag
16921 tcacaaaccc aagacgagat atcaaagtac ttacggcaat tgagatccgt cattgatacc
16981 acagtttatt gtagatttac cggtatagtc tcgtccatgc attacaaact tgatgaggtc
17041 ctttgggaaa tagagagttt caagtcggct gtgacgctag cagagggaga aggtgctggt
17101 gccttactat tgattcagaa ataccaagtt aagaccttat ttttcaacac gctagctact
17161 gagtccagta tagagtcaga aatagtatca ggaatgacta ctcctaggat gcttctacct
17221 gttatgtcaa aattccataa tgaccaaatt gagattattc ttaacaactc agcaagccaa
17281 ataacagaca taacaaatcc tacttggttt aaagaccaaa gagcaaggct acctaagcaa
17341 gtcgaggtta taaccatgga tgcagagaca acagagaata taaacagatc gaaattgtac
17401 gaagctgtat ataaattgat cttacaccat attgatccta gcgtattgaa agcagtggtc
17461 cttaaagtct ttctaagtga tactgagggt atgttatggc taaatgataa tttagccccg
17521 ttttttgcca ctggttattt aattaagcca ataacgtcaa gtgctagatc tagtgagtgg
17581 tatctttgtc tgacgaactt cttatcaact acacgtaaga tgccacacca aaaccatctc
17641 agttgtaaac aggtaatact tacggcattg caactgcaaa ttcaacgaag cccatactgg
17701 ctaagtcatt taactcagta tgctgactgt gagttacatt taagttatat ccgccttggt
17761 tttccatcat tagagaaagt actataccac aggtataacc tcgtcgattc aaaaagaggt
17821 ccactagtct ctatcactca gcacttagca catcttagag cagagattcg agaattaact
17881 aatgattata atcaacagcg acaaagtcgg actcaaacat atcactttat tcgtactgca
17941 aaaggacgaa tcacaaaact agtcaatgat tatttaaaat tctttcttat tgtgcaagca
18001 ttaaaacata atgggacatg gcaagctgag tttaagaaat taccagagtt gattagtgtg
18061 tgcaataggt tctaccatat tagagattgc aattgtgaag aacgtttctt agttcaaacc
18121 ttatatttac atagaatgca ggattctgaa gttaagctta tcgaaaggct gacagggctt
18181 ctgagtttat ttccggatgg tctctacagg tttgattgaa ttaccgtgca tagtatcctg
18241 atacttgcaa aggttggtta ttaacataca gattataaaa aactcataaa ttgctctcat
18301 acatcatatt gatctaatct caataaacaa ctatttaaat aacgaaagga gtccctatat
18361 tatatactat atttagcctc tctccctgcg tgataatcaa aaaattcaca atgcagcatg
18421 tgtgacatat tactgccgca atgaatttaa cgcaacataa taaactctgc actctttata
18481 attaagcttt aacgaaaggt ctgggctcat attgttattg atataataat gttgtatcaa
18541 tatcctgtca gatggaatag tgttttggtt gataacacaa cttcttaaaa caaaattgat
18601 ctttaagatt aagtttttta taattatcat tactttaatt tgtcgtttta aaaacggtga
18661 tagccttaat ctttgtgtaa aataagagat taggtgtaat aaccttaaca tttttgtcta
18721 gtaagctact atttcataca gaatgataaa attaaaagaa aaggcaggac tgtaaaatca
18781 gaaatacctt ctttacaata tagcagacta gataataatc ttcgtgttaa tgataattaa
18841 gacattgacc acgctcatca gaaggctcgc cagaataaac gttgcaaaaa ggattcctgg
18901 aaaaatggtc gcacacaaaa atttaaaaat aaatctattt cttctttttt gtgtgtcca
//Ebola Genome
Zaire ebolavirus isolate Ebola virus H.sapiens-tc/COD/1976/Yambuku-Mayinga, complete genome. NCBI Reference Sequence: NC_002549.1.
http://www.ncbi.nlm.nih.gov/nuccore/10313991?report=graph
![]()
![]()
![]()
LOCUS NC_002549 18959 bp cRNA linear VRL 27-AUG-2014
DEFINITION Zaire ebolavirus isolate Ebola virus
H.sapiens-tc/COD/1976/Yambuku-Mayinga, complete genome.
ACCESSION NC_002549
VERSION NC_002549.1 GI:10313991
DBLINK BioProject: PRJNA14703
KEYWORDS RefSeq.
SOURCE Zaire ebolavirus (ZEBOV)
ORGANISM Zaire ebolavirus
Viruses; ssRNA negative-strand viruses; Mononegavirales;
Filoviridae; Ebolavirus.
REFERENCE 1 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Volchkova,V.A., Chepurnov,A.A., Blinov,V.M.,
Dolnik,O., Netesov,S.V. and Feldmann,H.
TITLE Characterization of the L gene and 5' trailer region of Ebola virus
JOURNAL J. Gen. Virol. 80 (Pt 2), 355-362 (1999)
PUBMED 10073695
REFERENCE 2 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Volchkova,V.A., Slenczka,W., Klenk,H.D. and
Feldmann,H.
TITLE Release of viral glycoproteins during Ebola virus infection
JOURNAL Virology 245 (1), 110-119 (1998)
PUBMED 9614872
REFERENCE 3 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Feldmann,H., Volchkova,V.A. and Klenk,H.D.
TITLE Processing of the Ebola virus glycoprotein by the proprotein
convertase furin
JOURNAL Proc. Natl. Acad. Sci. U.S.A. 95 (10), 5762-5767 (1998)
PUBMED 9576958
REFERENCE 4 (bases 1 to 18959)
AUTHORS Volchkov,V.E., Becker,S., Volchkova,V.A., Ternovoj,V.A.,
Kotov,A.N., Netesov,S.V. and Klenk,H.D.
TITLE GP mRNA of Ebola virus is edited by the Ebola virus polymerase and
by T7 and vaccinia virus polymerases
JOURNAL Virology 214 (2), 421-430 (1995)
PUBMED 8553543
REFERENCE 5 (bases 1 to 18959)
AUTHORS Bukreyev,A.A., Volchkov,V.E., Blinov,V.M. and Netesov,S.V.
TITLE The VP35 and VP40 proteins of filoviruses. Homology between Marburg
and Ebola viruses
JOURNAL FEBS Lett. 322 (1), 41-46 (1993)
PUBMED 8482365
REFERENCE 6 (bases 1 to 18959)
CONSRTM NCBI Genome Project
TITLE Direct Submission
JOURNAL Submitted (27-SEP-2000) National Center for Biotechnology
Information, NIH, Bethesda, MD 20894, USA
REFERENCE 7 (bases 1 to 18959)
AUTHORS Volchkov,V.E.
TITLE Direct Submission
JOURNAL Submitted (02-JUN-2000) Institute of Virology, Philipps-University
Marburg, Robert-Koch-Str. 17, Marburg 35037, Germany
REMARK Sequence update by submitter
REFERENCE 8 (bases 1 to 18959)
AUTHORS Volchkov,V.E.
TITLE Direct Submission
JOURNAL Submitted (20-AUG-1998) Institute of Virology, Philipps-University
Marburg, Robert-Koch-Str. 17, Marburg 35037, Germany
COMMENT PROVISIONAL REFSEQ: This record has not yet been subject to final
NCBI review. The reference sequence is identical to AF086833.
COMPLETENESS: full length.
FEATURES Location/Qualifiers
source 1..18959
/organism="Zaire ebolavirus"
/mol_type="viral cRNA"
/isolate="Ebola virus
H.sapiens-tc/COD/1976/Yambuku-Mayinga"
/db_xref="taxon:186538"
5'UTR 1..55
/note="putative leader region"
/citation=[1]
/function="regulation or initiation of RNA replication"
gene 56..3026
/gene="NP"
/locus_tag="ZEBOVgp1"
/db_xref="GeneID:911830"
mRNA 56..3026
/gene="NP"
/locus_tag="ZEBOVgp1"
/product="nucleoprotein"
/db_xref="GeneID:911830"
misc_signal 56..67
/gene="NP"
/locus_tag="ZEBOVgp1"
/note="putative; transcription start signal"
/citation=[1]
CDS 470..2689
/gene="NP"
/locus_tag="ZEBOVgp1"
/function="encapsidation of genomic RNA"
/codon_start=1
/product="nucleoprotein"
/protein_id="NP_066243.1"
/db_xref="GI:10314000"
/db_xref="GeneID:911830"
/translation="MDSRPQKIWMAPSLTESDMDYHKILTAGLSVQQGIVRQRVIPVY
QVNNLEEICQLIIQAFEAGVDFQESADSFLLMLCLHHAYQGDYKLFLESGAVKYLEGH
GFRFEVKKRDGVKRLEELLPAVSSGKNIKRTLAAMPEEETTEANAGQFLSFASLFLPK
LVVGEKACLEKVQRQIQVHAEQGLIQYPTAWQSVGHMMVIFRLMRTNFLIKFLLIHQG
MHMVAGHDANDAVISNSVAQARFSGLLIVKTVLDHILQKTERGVRLHPLARTAKVKNE
VNSFKAALSSLAKHGEYAPFARLLNLSGVNNLEHGLFPQLSAIALGVATAHGSTLAGV
NVGEQYQQLREAATEAEKQLQQYAESRELDHLGLDDQEKKILMNFHQKKNEISFQQTN
AMVTLRKERLAKLTEAITAASLPKTSGHYDDDDDIPFPGPINDDDNPGHQDDDPTDSQ
DTTIPDVVVDPDDGSYGEYQSYSENGMNAPDDLVLFDLDEDDEDTKPVPNRSTKGGQQ
KNSQKGQHIEGRQTQSRPIQNVPGPHRTIHHASAPLTDNDRRNEPSGSTSPRMLTPIN
EEADPLDDADDETSSLPPLESDDEEQDRDGTSNRTPTVAPPAPVYRDHSEKKELPQDE
QQDQDHTQEARNQDSDNTQSEHSFEEMYRHILRSQGPFDAVLYYHMMKDEPVVFSTSD
GKEYTYPDSLEEEYPPWLTEKEAMNEENRFVTLDGQQFYWPVMNHKNKFMAILQHHQ"
misc_feature 524..2671
/gene="NP"
/locus_tag="ZEBOVgp1"
/note="Ebola nucleoprotein; Region: Ebola_NP; pfam05505"
/db_xref="CDD:147601"
polyA_signal 3015..3026
/gene="NP"
/locus_tag="ZEBOVgp1"
misc_feature 3027..3031
/note="intergenic region"
gene 3032..4407
/gene="VP35"
/locus_tag="ZEBOVgp2"
/db_xref="GeneID:911827"
mRNA 3032..4407
/gene="VP35"
/locus_tag="ZEBOVgp2"
/product="VP35"
/citation=[5]
/db_xref="GeneID:911827"
misc_signal 3032..3043
/gene="VP35"
/locus_tag="ZEBOVgp2"
/note="putative; transcription start signal"
/citation=[5]
CDS 3129..4151
/gene="VP35"
/locus_tag="ZEBOVgp2"
/function="polymerase complex protein"
/citation=[5]
/codon_start=1
/product="polymerase complex protein"
/protein_id="NP_066244.1"
/db_xref="GI:10313992"
/db_xref="GeneID:911827"
/translation="MTTRTKGRGHTAATTQNDRMPGPELSGWISEQLMTGRIPVSDIF
CDIENNPGLCYASQMQQTKPNPKTRNSQTQTDPICNHSFEEVVQTLASLATVVQQQTI
ASESLEQRITSLENGLKPVYDMAKTISSLNRVCAEMVAKYDLLVMTTGRATATAAATE
AYWAEHGQPPPGPSLYEESAIRGKIESRDETVPQSVREAFNNLNSTTSLTEENFGKPD
ISAKDLRNIMYDHLPGFGTAFHQLVQVICKLGKDSNSLDIIHAEFQASLAEGDSPQCA
LIQITKRVPIFQDAAPPVIHIRSRGDIPRACQKSLRPVPPSPKIDRGWVCVFQLQDGK
TLGLKI"
misc_feature 3186..4148
/gene="VP35"
/locus_tag="ZEBOVgp2"
/note="Filoviridae VP35; Region: Filo_VP35; pfam02097"
/db_xref="CDD:145320"
gene 4390..5894
/gene="VP40"
/locus_tag="ZEBOVgp3"
/db_xref="GeneID:911825"
mRNA 4390..5894
/gene="VP40"
/locus_tag="ZEBOVgp3"
/product="VP40"
/citation=[5]
/db_xref="GeneID:911825"
misc_signal 4390..4401
/gene="VP40"
/locus_tag="ZEBOVgp3"
/note="transcription start signal"
/citation=[5]
polyA_signal 4397..4407
/gene="VP35"
/locus_tag="ZEBOVgp2"
/citation=[5]
CDS 4479..5459
/gene="VP40"
/locus_tag="ZEBOVgp3"
/citation=[5]
/codon_start=1
/product="matrix protein"
/protein_id="NP_066245.1"
/db_xref="GI:10313993"
/db_xref="GeneID:911825"
/translation="MRRVILPTAPPEYMEAIYPVRSNSTIARGGNSNTGFLTPESVNG
DTPSNPLRPIADDTIDHASHTPGSVSSAFILEAMVNVISGPKVLMKQIPIWLPLGVAD
QKTYSFDSTTAAIMLASYTITHFGKATNPLVRVNRLGPGIPDHPLRLLRIGNQAFLQE
FVLPPVQLPQYFTFDLTALKLITQPLPAATWTDDTPTGSNGALRPGISFHPKLRPILL
PNKSGKKGNSADLTSPEKIQAIMTSLQDFKIVPIDPTKNIMGIEVPETLVHKLTGKKV
TSKNGQPIIPVLLPKYIGLDPVAPGDLTMVITQDCDTCHSPASLPAVIEK"
misc_feature 4479..5363
/gene="VP40"
/locus_tag="ZEBOVgp3"
/note="Matrix protein VP40; Region: VP40; pfam07447"
/db_xref="CDD:116068"
polyA_signal 5883..5894
/gene="VP40"
/locus_tag="ZEBOVgp3"
/citation=[5]
misc_feature 5895..5899
/note="intergenic region"
gene 5900..8305
/gene="GP"
/locus_tag="ZEBOVgp4"
/db_xref="GeneID:911829"
mRNA 5900..8305
/gene="GP"
/locus_tag="ZEBOVgp4"
/product="sGP"
/note="unedited mRNA"
/citation=[4]
/db_xref="GeneID:911829"
misc_signal 5900..5911
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="putative; transcription start signal"
/citation=[4]
CDS join(6039..6923,6923..8068)
/gene="GP"
/locus_tag="ZEBOVgp4"
/function="receptor binding and fusion"
/artificial_location="low-quality sequence region"
/note="virion spike glycoprotein precursor; an addition A
residue is inserted during transcription; encodes two
disulfide linked subunits GP1 and GP2"
/citation=[2]
/citation=[3]
/citation=[4]
/codon_start=1
/product="spike glycoprotein"
/protein_id="NP_066246.1"
/db_xref="GI:10313995"
/db_xref="GeneID:911829"
/translation="MGVTGILQLPRDRFKRTSFFLWVIILFQRTFSIPLGVIHNSTLQ
VSDVDKLVCRDKLSSTNQLRSVGLNLEGNGVATDVPSATKRWGFRSGVPPKVVNYEAG
EWAENCYNLEIKKPDGSECLPAAPDGIRGFPRCRYVHKVSGTGPCAGDFAFHKEGAFF
LYDRLASTVIYRGTTFAEGVVAFLILPQAKKDFFSSHPLREPVNATEDPSSGYYSTTI
RYQATGFGTNETEYLFEVDNLTYVQLESRFTPQFLLQLNETIYTSGKRSNTTGKLIWK
VNPEIDTTIGEWAFWETKKNLTRKIRSEELSFTVVSNGAKNISGQSPARTSSDPGTNT
TTEDHKIMASENSSAMVQVHSQGREAAVSHLTTLATISTSPQSLTTKPGPDNSTHNTP
VYKLDISEATQVEQHHRRTDNDSTASDTPSATTAAGPPKAENTNTSKSTDFLDPATTT
SPQNHSETAGNNNTHHQDTGEESASSGKLGLITNTIAGVAGLITGGRRTRREAIVNAQ
PKCNPNLHYWTTQDEGAAIGLAWIPYFGPAAEGIYIEGLMHNQDGLICGLRQLANETT
QALQLFLRATTELRTFSILNRKAIDFLLQRWGGTCHILGPDCCIEPHDWTKNITDKID
QIIHDFVDKTLPDQGDNDNWWTGWRQWIPAGIGVTGVIIAVIALFCICKFVF"
misc_feature 7529..7540
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="encodes the glycoprotein cleavage site, precursor
GP is cleaved by subtilisin-like cellular protease furin
into subunits GP1 and GP2 that are linked by a disulfide
bond"
/citation=[3]
misc_feature 7793..7870
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="immunosuppressive motif; other site"
misc_feature 7988..8053
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="transmembrane anchor; transmembrane region"
misc_feature 7706..7924
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="heptad repeat 1-heptad repeat 2 region of the
transmembrane subunit of Filoviridae viruses, Ebola virus
and Marburg virus, and related domains; Region:
Ebola-like_HR1-HR2; cd09850"
/db_xref="CDD:197367"
misc_feature join(6081..6923,6923..7153)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Filovirus glycoprotein; Region: Filo_glycop;
pfam01611"
/db_xref="CDD:110602"
misc_feature 7706..7732
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1A; other site"
/db_xref="CDD:197367"
misc_feature 7733..7762
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1B; other site"
/db_xref="CDD:197367"
misc_feature 7763..7783
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1C; other site"
/db_xref="CDD:197367"
misc_feature 7784..7831
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1D; other site"
/db_xref="CDD:197367"
misc_feature 7787..7837
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="immunosuppressive region; other site"
/db_xref="CDD:197367"
misc_feature order(7838..7858,7859..7861)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="CX(6,7)C motif; other site"
/db_xref="CDD:197367"
misc_feature 7886..7924
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR2; other site"
/db_xref="CDD:197367"
misc_feature order(7784..7786,7793..7795)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Cl binding site [ion binding]; other site"
/db_xref="CDD:197367"
misc_feature order(7706..7714,7718..7723,7727..7732,7736..7744,
7748..7756,7760..7765,7769..7777,7781..7807,7811..7819,
7823..7828,7844..7849,7856..7858,7865..7876,7880..7882,
7889..7894,7901..7903,7910..7915,7922..7924)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="homotrimer interface [polypeptide binding]; other
site"
/db_xref="CDD:197367"
misc_feature order(7706..7714,7718..7726,7730..7735,7739..7747,
7754..7768,7772..7783,7787..7792,7796..7804,7808..7813,
7817..7819)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="HR1-GP1 interface [polypeptide binding]; other
site"
/db_xref="CDD:197367"
CDS 6039..7133
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="sGP, small non-structural, secreted glycoprotein;
sGP secreted as a anti-parallel oriented homodimer"
/citation=[4]
/codon_start=1
/product="small secreted glycoprotein"
/protein_id="NP_066247.1"
/db_xref="GI:10313994"
/db_xref="GeneID:911829"
/translation="MGVTGILQLPRDRFKRTSFFLWVIILFQRTFSIPLGVIHNSTLQ
VSDVDKLVCRDKLSSTNQLRSVGLNLEGNGVATDVPSATKRWGFRSGVPPKVVNYEAG
EWAENCYNLEIKKPDGSECLPAAPDGIRGFPRCRYVHKVSGTGPCAGDFAFHKEGAFF
LYDRLASTVIYRGTTFAEGVVAFLILPQAKKDFFSSHPLREPVNATEDPSSGYYSTTI
RYQATGFGTNETEYLFEVDNLTYVQLESRFTPQFLLQLNETIYTSGKRSNTTGKLIWK
VNPEIDTTIGEWAFWETKKTSLEKFAVKSCLSQLYQTEPKTSVVRVRRELLPTQGPTQ
QLKTTKSWLQKIPLQWFKCTVKEGKLQCRI"
misc_feature 6081..7130
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Filovirus glycoprotein; Region: Filo_glycop;
pfam01611"
/db_xref="CDD:110602"
CDS join(6039..6922,6924..6933)
/gene="GP"
/locus_tag="ZEBOVgp4"
/artificial_location="low-quality sequence region"
/note="ssGP; second non-structural secreted glycoprotein;
secreted in a monomeric form; one A residue is deleted or
two additional A residues are inserted at the editing site
during transcription of the GP gene"
/citation=[4]
/codon_start=1
/product="second secreted glycoprotein"
/protein_id="NP_066248.1"
/db_xref="GI:10313996"
/db_xref="GeneID:911829"
/translation="MGVTGILQLPRDRFKRTSFFLWVIILFQRTFSIPLGVIHNSTLQ
VSDVDKLVCRDKLSSTNQLRSVGLNLEGNGVATDVPSATKRWGFRSGVPPKVVNYEAG
EWAENCYNLEIKKPDGSECLPAAPDGIRGFPRCRYVHKVSGTGPCAGDFAFHKEGAFF
LYDRLASTVIYRGTTFAEGVVAFLILPQAKKDFFSSHPLREPVNATEDPSSGYYSTTI
RYQATGFGTNETEYLFEVDNLTYVQLESRFTPQFLLQLNETIYTSGKRSNTTGKLIWK
VNPEIDTTIGEWAFWETKKPH"
misc_feature join(6081..6922,6924..>6924)
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="Filovirus glycoprotein; Region: Filo_glycop;
pfam01611"
/db_xref="CDD:110602"
misc_signal 6918..6924
/gene="GP"
/locus_tag="ZEBOVgp4"
/note="additional A residues are inserted or deleted
during transcription of the GP gene by the viral
polymerase"
/citation=[4]
/function="RNA editing"
gene 8288..9740
/gene="VP30"
/locus_tag="ZEBOVgp5"
/db_xref="GeneID:911826"
mRNA 8288..9740
/gene="VP30"
/locus_tag="ZEBOVgp5"
/product="VP30"
/db_xref="GeneID:911826"
misc_signal 8288..8299
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="putative; transcription start signal"
polyA_signal 8295..8305
/gene="GP"
/locus_tag="ZEBOVgp4"
/citation=[4]
CDS 8509..9375
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="polymerase complex protein"
/codon_start=1
/product="minor nucleoprotein"
/protein_id="NP_066249.1"
/db_xref="GI:10313997"
/db_xref="GeneID:911826"
/translation="MEASYERGRPRAARQHSRDGHDHHVRARSSSRENYRGEYRQSRS
ASQVRVPTVFHKKRVEPLTVPPAPKDICPTLKKGFLCDSSFCKKDHQLESLTDRELLL
LIARKTCGSVEQQLNITAPKDSRLANPTADDFQQEEGPKITLLTLIKTAEHWARQDIR
TIEDSKLRALLTLCAVMTRKFSKSQLSLLCETHLRREGLGQDQAEPVLEVYQRLHSDK
GGSFEAALWQQWDRQSLIMFITAFLNIALQLPCESSAVVVSGLRTLVPQSDNEEASTN
PGTCSWSDEGTP"
misc_feature 8932..9321
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="Ebola virus-specific transcription factor VP30;
Region: Transcript_VP30; pfam11507"
/db_xref="CDD:151944"
polyA_signal 9730..9740
/gene="VP30"
/locus_tag="ZEBOVgp5"
/note="putative"
misc_feature 9741..9884
/note="intergenic region"
gene 9885..11518
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="putative"
/db_xref="GeneID:911828"
mRNA 9885..11496
/gene="VP24"
/locus_tag="ZEBOVgp6"
/product="VP24"
/db_xref="GeneID:911828"
misc_signal 9885..9896
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="transcription start signal"
CDS 10345..11100
/gene="VP24"
/locus_tag="ZEBOVgp6"
/codon_start=1
/product="membrane-associated protein"
/protein_id="NP_066250.1"
/db_xref="GI:10313998"
/db_xref="GeneID:911828"
/translation="MAKATGRYNLISPKKDLEKGVVLSDLCNFLVSQTIQGWKVYWAG
IEFDVTHKGMALLHRLKTNDFAPAWSMTRNLFPHLFQNPNSTIESPLWALRVILAAGI
QDQLIDQSLIEPLAGALGLISDWLLTTNTNHFNMRTQRVKEQLSLKMLSLIRSNILKF
INKLDALHVVNYNGLLSSIEIGTQNHTIIITRTNMGFLVELQEPDKSAMNRMKPGPAK
FSLLHESTLKAFTQGSSTRMQSLILEFNSSLAI"
misc_feature 10369..11040
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="Filovirus membrane-associated protein VP24; Region:
Filo_VP24; pfam06389"
/db_xref="CDD:253701"
polyA_signal 11485..11496
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="putative"
misc_feature 11497..11500
/gene="VP24"
/locus_tag="ZEBOVgp6"
/note="intergenic region"
gene 11501..18282
/gene="L"
/locus_tag="ZEBOVgp7"
/db_xref="GeneID:911824"
mRNA 11501..18282
/gene="L"
/locus_tag="ZEBOVgp7"
/product="polymerase"
/citation=[1]
/db_xref="GeneID:911824"
misc_signal 11501..11512
/gene="L"
/locus_tag="ZEBOVgp7"
/note="transcription start signal"
/citation=[1]
polyA_signal 11508..11518
/gene="VP24"
/locus_tag="ZEBOVgp6"
CDS 11581..18219
/gene="L"
/locus_tag="ZEBOVgp7"
/function="synthesis of viral RNAs; transcriptional RNA
editing"
/note="polymerase"
/citation=[1]
/codon_start=1
/product="RNA-dependent RNA polymerase"
/protein_id="NP_066251.1"
/db_xref="GI:10313999"
/db_xref="GeneID:911824"
/translation="MATQHTQYPDARLSSPIVLDQCDLVTRACGLYSSYSLNPQLRNC
KLPKHIYRLKYDVTVTKFLSDVPVATLPIDFIVPVLLKALSGNGFCPVEPRCQQFLDE
IIKYTMQDALFLKYYLKNVGAQEDCVDEHFQEKILSSIQGNEFLHQMFFWYDLAILTR
RGRLNRGNSRSTWFVHDDLIDILGYGDYVFWKIPISMLPLNTQGIPHAAMDWYQASVF
KEAVQGHTHIVSVSTADVLIMCKDLITCRFNTTLISKIAEIEDPVCSDYPNFKIVSML
YQSGDYLLSILGSDGYKIIKFLEPLCLAKIQLCSKYTERKGRFLTQMHLAVNHTLEEI
TEMRALKPSQAQKIREFHRTLIRLEMTPQQLCELFSIQKHWGHPVLHSETAIQKVKKH
ATVLKALRPIVIFETYCVFKYSIAKHYFDSQGSWYSVTSDRNLTPGLNSYIKRNQFPP
LPMIKELLWEFYHLDHPPLFSTKIISDLSIFIKDRATAVERTCWDAVFEPNVLGYNPP
HKFSTKRVPEQFLEQENFSIENVLSYAQKLEYLLPQYRNFSFSLKEKELNVGRTFGKL
PYPTRNVQTLCEALLADGLAKAFPSNMMVVTEREQKESLLHQASWHHTSDDFGEHATV
RGSSFVTDLEKYNLAFRYEFTAPFIEYCNRCYGVKNVFNWMHYTIPQCYMHVSDYYNP
PHNLTLENRDNPPEGPSSYRGHMGGIEGLQQKLWTSISCAQISLVEIKTGFKLRSAVM
GDNQCITVLSVFPLETDADEQEQSAEDNAARVAASLAKVTSACGIFLKPDETFVHSGF
IYFGKKQYLNGVQLPQSLKTATRMAPLSDAIFDDLQGTLASIGTAFERSISETRHIFP
CRITAAFHTFFSVRILQYHHLGFNKGFDLGQLTLGKPLDFGTISLALAVPQVLGGLSF
LNPEKCFYRNLGDPVTSGLFQLKTYLRMIEMDDLFLPLIAKNPGNCTAIDFVLNPSGL
NVPGSQDLTSFLRQIVRRTITLSAKNKLINTLFHASADFEDEMVCKWLLSSTPVMSRF
AADIFSRTPSGKRLQILGYLEGTRTLLASKIINNNTETPVLDRLRKITLQRWSLWFSY
LDHCDNILAEALTQITCTVDLAQILREYSWAHILEGRPLIGATLPCMIEQFKVFWLKP
YEQCPQCSNAKQPGGKPFVSVAVKKHIVSAWPNASRISWTIGDGIPYIGSRTEDKIGQ
PAIKPKCPSAALREAIELASRLTWVTQGSSNSDLLIKPFLEARVNLSVQEILQMTPSH
YSGNIVHRYNDQYSPHSFMANRMSNSATRLIVSTNTLGEFSGGGQSARDSNIIFQNVI
NYAVALFDIKFRNTEATDIQYNRAHLHLTKCCTREVPAQYLTYTSTLDLDLTRYRENE
LIYDSNPLKGGLNCNISFDNPFFQGKRLNIIEDDLIRLPHLSGWELAKTIMQSIISDS
NNSSTDPISSGETRSFTTHFLTYPKIGLLYSFGAFVSYYLGNTILRTKKLTLDNFLYY
LTTQIHNLPHRSLRILKPTFKHASVMSRLMSIDPHFSIYIGGAAGDRGLSDAARLFLR
TSISSFLTFVKEWIINRGTIVPLWIVYPLEGQNPTPVNNFLYQIVELLVHDSSRQQAF
KTTISDHVHPHDNLVYTCKSTASNFFHASLAYWRSRHRNSNRKYLARDSSTGSSTNNS
DGHIERSQEQTTRDPHDGTERNLVLQMSHEIKRTTIPQENTHQGPSFQSFLSDSACGT
ANPKLNFDRSRHNVKFQDHNSASKREGHQIISHRLVLPFFTLSQGTRQLTSSNESQTQ
DEISKYLRQLRSVIDTTVYCRFTGIVSSMHYKLDEVLWEIESFKSAVTLAEGEGAGAL
LLIQKYQVKTLFFNTLATESSIESEIVSGMTTPRMLLPVMSKFHNDQIEIILNNSASQ
ITDITNPTWFKDQRARLPKQVEVITMDAETTENINRSKLYEAVYKLILHHIDPSVLKA
VVLKVFLSDTEGMLWLNDNLAPFFATGYLIKPITSSARSSEWYLCLTNFLSTTRKMPH
QNHLSCKQVILTALQLQIQRSPYWLSHLTQYADCELHLSYIRLGFPSLEKVLYHRYNL
VDSKRGPLVSITQHLAHLRAEIRELTNDYNQQRQSRTQTYHFIRTAKGRITKLVNDYL
KFFLIVQALKHNGTWQAEFKKLPELISVCNRFYHIRDCNCEERFLVQTLYLHRMQDSE
VKLIERLTGLLSLFPDGLYRFD"
misc_feature 11608..14853
/gene="L"
/locus_tag="ZEBOVgp7"
/note="Mononegavirales RNA dependent RNA polymerase;
Region: Mononeg_RNA_pol; pfam00946"
/db_xref="CDD:250248"
misc_feature 15223..18192
/gene="L"
/locus_tag="ZEBOVgp7"
/note="mRNA capping enzyme, paramyxovirus family; Region:
paramyx_RNAcap; TIGR04198"
/db_xref="CDD:234496"
polyA_signal 18272..18282
/gene="L"
/locus_tag="ZEBOVgp7"
/citation=[1]
3'UTR 18283..18959
/note="putative trailer region"
/citation=[1]
/function="regulation or initiation of RNA replication"
ORIGIN
1 cggacacaca aaaagaaaga agaattttta ggatcttttg tgtgcgaata actatgagga
61 agattaataa ttttcctctc attgaaattt atatcggaat ttaaattgaa attgttactg
121 taatcacacc tggtttgttt cagagccaca tcacaaagat agagaacaac ctaggtctcc
181 gaagggagca agggcatcag tgtgctcagt tgaaaatccc ttgtcaacac ctaggtctta
241 tcacatcaca agttccacct cagactctgc agggtgatcc aacaacctta atagaaacat
301 tattgttaaa ggacagcatt agttcacagt caaacaagca agattgagaa ttaaccttgg
361 ttttgaactt gaacacttag gggattgaag attcaacaac cctaaagctt ggggtaaaac
421 attggaaata gttaaaagac aaattgctcg gaatcacaaa attccgagta tggattctcg
481 tcctcagaaa atctggatgg cgccgagtct cactgaatct gacatggatt accacaagat
541 cttgacagca ggtctgtccg ttcaacaggg gattgttcgg caaagagtca tcccagtgta
601 tcaagtaaac aatcttgaag aaatttgcca acttatcata caggcctttg aagcaggtgt
661 tgattttcaa gagagtgcgg acagtttcct tctcatgctt tgtcttcatc atgcgtacca
721 gggagattac aaacttttct tggaaagtgg cgcagtcaag tatttggaag ggcacgggtt
781 ccgttttgaa gtcaagaagc gtgatggagt gaagcgcctt gaggaattgc tgccagcagt
841 atctagtgga aaaaacatta agagaacact tgctgccatg ccggaagagg agacaactga
901 agctaatgcc ggtcagtttc tctcctttgc aagtctattc cttccgaaat tggtagtagg
961 agaaaaggct tgccttgaga aggttcaaag gcaaattcaa gtacatgcag agcaaggact
1021 gatacaatat ccaacagctt ggcaatcagt aggacacatg atggtgattt tccgtttgat
1081 gcgaacaaat tttctgatca aatttctcct aatacaccaa gggatgcaca tggttgccgg
1141 gcatgatgcc aacgatgctg tgatttcaaa ttcagtggct caagctcgtt tttcaggctt
1201 attgattgtc aaaacagtac ttgatcatat cctacaaaag acagaacgag gagttcgtct
1261 ccatcctctt gcaaggaccg ccaaggtaaa aaatgaggtg aactccttta aggctgcact
1321 cagctccctg gccaagcatg gagagtatgc tcctttcgcc cgacttttga acctttctgg
1381 agtaaataat cttgagcatg gtcttttccc tcaactatcg gcaattgcac tcggagtcgc
1441 cacagcacac gggagtaccc tcgcaggagt aaatgttgga gaacagtatc aacaactcag
1501 agaggctgcc actgaggctg agaagcaact ccaacaatat gcagagtctc gcgaacttga
1561 ccatcttgga cttgatgatc aggaaaagaa aattcttatg aacttccatc agaaaaagaa
1621 cgaaatcagc ttccagcaaa caaacgctat ggtaactcta agaaaagagc gcctggccaa
1681 gctgacagaa gctatcactg ctgcgtcact gcccaaaaca agtggacatt acgatgatga
1741 tgacgacatt ccctttccag gacccatcaa tgatgacgac aatcctggcc atcaagatga
1801 tgatccgact gactcacagg atacgaccat tcccgatgtg gtggttgatc ccgatgatgg
1861 aagctacggc gaataccaga gttactcgga aaacggcatg aatgcaccag atgacttggt
1921 cctattcgat ctagacgagg acgacgagga cactaagcca gtgcctaata gatcgaccaa
1981 gggtggacaa cagaagaaca gtcaaaaggg ccagcatata gagggcagac agacacaatc
2041 caggccaatt caaaatgtcc caggccctca cagaacaatc caccacgcca gtgcgccact
2101 cacggacaat gacagaagaa atgaaccctc cggctcaacc agccctcgca tgctgacacc
2161 aattaacgaa gaggcagacc cactggacga tgccgacgac gagacgtcta gccttccgcc
2221 cttggagtca gatgatgaag agcaggacag ggacggaact tccaaccgca cacccactgt
2281 cgccccaccg gctcccgtat acagagatca ctctgaaaag aaagaactcc cgcaagacga
2341 gcaacaagat caggaccaca ctcaagaggc caggaaccag gacagtgaca acacccagtc
2401 agaacactct tttgaggaga tgtatcgcca cattctaaga tcacaggggc catttgatgc
2461 tgttttgtat tatcatatga tgaaggatga gcctgtagtt ttcagtacca gtgatggcaa
2521 agagtacacg tatccagact cccttgaaga ggaatatcca ccatggctca ctgaaaaaga
2581 ggctatgaat gaagagaata gatttgttac attggatggt caacaatttt attggccggt
2641 gatgaatcac aagaataaat tcatggcaat cctgcaacat catcagtgaa tgagcatgga
2701 acaatgggat gattcaaccg acaaatagct aacattaagt agtcaaggaa cgaaaacagg
2761 aagaattttt gatgtctaag gtgtgaatta ttatcacaat aaaagtgatt cttatttttg
2821 aatttaaagc tagcttatta ttactagccg tttttcaaag ttcaatttga gtcttaatgc
2881 aaataggcgt taagccacag ttatagccat aattgtaact caatattcta actagcgatt
2941 tatctaaatt aaattacatt atgcttttat aacttaccta ctagcctgcc caacatttac
3001 acgatcgttt tataattaag aaaaaactaa tgatgaagat taaaaccttc atcatcctta
3061 cgtcaattga attctctagc actcgaagct tattgtcttc aatgtaaaag aaaagctggt
3121 ctaacaagat gacaactaga acaaagggca ggggccatac tgcggccacg actcaaaacg
3181 acagaatgcc aggccctgag ctttcgggct ggatctctga gcagctaatg accggaagaa
3241 ttcctgtaag cgacatcttc tgtgatattg agaacaatcc aggattatgc tacgcatccc
3301 aaatgcaaca aacgaagcca aacccgaaga cgcgcaacag tcaaacccaa acggacccaa
3361 tttgcaatca tagttttgag gaggtagtac aaacattggc ttcattggct actgttgtgc
3421 aacaacaaac catcgcatca gaatcattag aacaacgcat tacgagtctt gagaatggtc
3481 taaagccagt ttatgatatg gcaaaaacaa tctcctcatt gaacagggtt tgtgctgaga
3541 tggttgcaaa atatgatctt ctggtgatga caaccggtcg ggcaacagca accgctgcgg
3601 caactgaggc ttattgggcc gaacatggtc aaccaccacc tggaccatca ctttatgaag
3661 aaagtgcgat tcggggtaag attgaatcta gagatgagac cgtccctcaa agtgttaggg
3721 aggcattcaa caatctaaac agtaccactt cactaactga ggaaaatttt gggaaacctg
3781 acatttcggc aaaggatttg agaaacatta tgtatgatca cttgcctggt tttggaactg
3841 ctttccacca attagtacaa gtgatttgta aattgggaaa agatagcaac tcattggaca
3901 tcattcatgc tgagttccag gccagcctgg ctgaaggaga ctctcctcaa tgtgccctaa
3961 ttcaaattac aaaaagagtt ccaatcttcc aagatgctgc tccacctgtc atccacatcc
4021 gctctcgagg tgacattccc cgagcttgcc agaaaagctt gcgtccagtc ccaccatcgc
4081 ccaagattga tcgaggttgg gtatgtgttt ttcagcttca agatggtaaa acacttggac
4141 tcaaaatttg agccaatctc ccttccctcc gaaagaggcg aataatagca gaggcttcaa
4201 ctgctgaact atagggtacg ttacattaat gatacacttg tgagtatcag ccctggataa
4261 tataagtcaa ttaaacgacc aagataaaat tgttcatatc tcgctagcag cttaaaatat
4321 aaatgtaata ggagctatat ctctgacagt attataatca attgttatta agtaacccaa
4381 accaaaagtg atgaagatta agaaaaacct acctcggctg agagagtgtt ttttcattaa
4441 ccttcatctt gtaaacgttg agcaaaattg ttaaaaatat gaggcgggtt atattgccta
4501 ctgctcctcc tgaatatatg gaggccatat accctgtcag gtcaaattca acaattgcta
4561 gaggtggcaa cagcaataca ggcttcctga caccggagtc agtcaatggg gacactccat
4621 cgaatccact caggccaatt gccgatgaca ccatcgacca tgccagccac acaccaggca
4681 gtgtgtcatc agcattcatc cttgaagcta tggtgaatgt catatcgggc cccaaagtgc
4741 taatgaagca aattccaatt tggcttcctc taggtgtcgc tgatcaaaag acctacagct
4801 ttgactcaac tacggccgcc atcatgcttg cttcatacac tatcacccat ttcggcaagg
4861 caaccaatcc acttgtcaga gtcaatcggc tgggtcctgg aatcccggat catcccctca
4921 ggctcctgcg aattggaaac caggctttcc tccaggagtt cgttcttccg ccagtccaac
4981 taccccagta tttcaccttt gatttgacag cactcaaact gatcacccaa ccactgcctg
5041 ctgcaacatg gaccgatgac actccaacag gatcaaatgg agcgttgcgt ccaggaattt
5101 catttcatcc aaaacttcgc cccattcttt tacccaacaa aagtgggaag aaggggaaca
5161 gtgccgatct aacatctccg gagaaaatcc aagcaataat gacttcactc caggacttta
5221 agatcgttcc aattgatcca accaaaaata tcatgggaat cgaagtgcca gaaactctgg
5281 tccacaagct gaccggtaag aaggtgactt ctaaaaatgg acaaccaatc atccctgttc
5341 ttttgccaaa gtacattggg ttggacccgg tggctccagg agacctcacc atggtaatca
5401 cacaggattg tgacacgtgt cattctcctg caagtcttcc agctgtgatt gagaagtaat
5461 tgcaataatt gactcagatc cagttttata gaatcttctc agggatagtg ataacatcta
5521 tttagtaatc cgtccattag aggagacact tttaattgat caatatacta aaggtgcttt
5581 acaccattgt cttttttctc tcctaaatgt agaacttaac aaaagactca taatatactt
5641 gtttttaaag gattgattga tgaaagatca taactaataa cattacaaat aatcctacta
5701 taatcaatac ggtgattcaa atgttaatct ttctcattgc acatactttt tgcccttatc
5761 ctcaaattgc ctgcatgctt acatctgagg atagccagtg tgacttggat tggaaatgtg
5821 gagaaaaaat cgggacccat ttctaggttg ttcacaatcc aagtacagac attgcccttc
5881 taattaagaa aaaatcggcg atgaagatta agccgacagt gagcgtaatc ttcatctctc
5941 ttagattatt tgttttccag agtaggggtc gtcaggtcct tttcaatcgt gtaaccaaaa
6001 taaactccac tagaaggata ttgtggggca acaacacaat gggcgttaca ggaatattgc
6061 agttacctcg tgatcgattc aagaggacat cattctttct ttgggtaatt atccttttcc
6121 aaagaacatt ttccatccca cttggagtca tccacaatag cacattacag gttagtgatg
6181 tcgacaaact agtttgtcgt gacaaactgt catccacaaa tcaattgaga tcagttggac
6241 tgaatctcga agggaatgga gtggcaactg acgtgccatc tgcaactaaa agatggggct
6301 tcaggtccgg tgtcccacca aaggtggtca attatgaagc tggtgaatgg gctgaaaact
6361 gctacaatct tgaaatcaaa aaacctgacg ggagtgagtg tctaccagca gcgccagacg
6421 ggattcgggg cttcccccgg tgccggtatg tgcacaaagt atcaggaacg ggaccgtgtg
6481 ccggagactt tgccttccat aaagagggtg ctttcttcct gtatgatcga cttgcttcca
6541 cagttatcta ccgaggaacg actttcgctg aaggtgtcgt tgcatttctg atactgcccc
6601 aagctaagaa ggacttcttc agctcacacc ccttgagaga gccggtcaat gcaacggagg
6661 acccgtctag tggctactat tctaccacaa ttagatatca ggctaccggt tttggaacca
6721 atgagacaga gtacttgttc gaggttgaca atttgaccta cgtccaactt gaatcaagat
6781 tcacaccaca gtttctgctc cagctgaatg agacaatata tacaagtggg aaaaggagca
6841 ataccacggg aaaactaatt tggaaggtca accccgaaat tgatacaaca atcggggagt
6901 gggccttctg ggaaactaaa aaaacctcac tagaaaaatt cgcagtgaag agttgtcttt
6961 cacagttgta tcaaacggag ccaaaaacat cagtggtcag agtccggcgc gaacttcttc
7021 cgacccaggg accaacacaa caactgaaga ccacaaaatc atggcttcag aaaattcctc
7081 tgcaatggtt caagtgcaca gtcaaggaag ggaagctgca gtgtcgcatc taacaaccct
7141 tgccacaatc tccacgagtc cccaatccct cacaaccaaa ccaggtccgg acaacagcac
7201 ccataataca cccgtgtata aacttgacat ctctgaggca actcaagttg aacaacatca
7261 ccgcagaaca gacaacgaca gcacagcctc cgacactccc tctgccacga ccgcagccgg
7321 acccccaaaa gcagagaaca ccaacacgag caagagcact gacttcctgg accccgccac
7381 cacaacaagt ccccaaaacc acagcgagac cgctggcaac aacaacactc atcaccaaga
7441 taccggagaa gagagtgcca gcagcgggaa gctaggctta attaccaata ctattgctgg
7501 agtcgcagga ctgatcacag gcgggagaag aactcgaaga gaagcaattg tcaatgctca
7561 acccaaatgc aaccctaatt tacattactg gactactcag gatgaaggtg ctgcaatcgg
7621 actggcctgg ataccatatt tcgggccagc agccgaggga atttacatag aggggctaat
7681 gcacaatcaa gatggtttaa tctgtgggtt gagacagctg gccaacgaga cgactcaagc
7741 tcttcaactg ttcctgagag ccacaactga gctacgcacc ttttcaatcc tcaaccgtaa
7801 ggcaattgat ttcttgctgc agcgatgggg cggcacatgc cacattctgg gaccggactg
7861 ctgtatcgaa ccacatgatt ggaccaagaa cataacagac aaaattgatc agattattca
7921 tgattttgtt gataaaaccc ttccggacca gggggacaat gacaattggt ggacaggatg
7981 gagacaatgg ataccggcag gtattggagt tacaggcgtt ataattgcag ttatcgcttt
8041 attctgtata tgcaaatttg tcttttagtt tttcttcaga ttgcttcatg gaaaagctca
8101 gcctcaaatc aatgaaacca ggatttaatt atatggatta cttgaatcta agattacttg
8161 acaaatgata atataataca ctggagcttt aaacatagcc aatgtgattc taactccttt
8221 aaactcacag ttaatcataa acaaggtttg acatcaatct agttatctct ttgagaatga
8281 taaacttgat gaagattaag aaaaaggtaa tctttcgatt atctttaatc ttcatccttg
8341 attctacaat catgacagtt gtctttagtg acaagggaaa gaagcctttt tattaagttg
8401 taataatcag atctgcgaac cggtagagtt tagttgcaac ctaacacaca taaagcattg
8461 gtcaaaaagt caatagaaat ttaaacagtg agtggagaca acttttaaat ggaagcttca
8521 tatgagagag gacgcccacg agctgccaga cagcattcaa gggatggaca cgaccaccat
8581 gttcgagcac gatcatcatc cagagagaat tatcgaggtg agtaccgtca atcaaggagc
8641 gcctcacaag tgcgcgttcc tactgtattt cataagaaga gagttgaacc attaacagtt
8701 cctccagcac ctaaagacat atgtccgacc ttgaaaaaag gatttttgtg tgacagtagt
8761 ttttgcaaaa aagatcacca gttggagagt ttaactgata gggaattact cctactaatc
8821 gcccgtaaga cttgtggatc agtagaacaa caattaaata taactgcacc caaggactcg
8881 cgcttagcaa atccaacggc tgatgatttc cagcaagagg aaggtccaaa aattaccttg
8941 ttgacactga tcaagacggc agaacactgg gcgagacaag acatcagaac catagaggat
9001 tcaaaattaa gagcattgtt gactctatgt gctgtgatga cgaggaaatt ctcaaaatcc
9061 cagctgagtc ttttatgtga gacacaccta aggcgcgagg ggcttgggca agatcaggca
9121 gaacccgttc tcgaagtata tcaacgatta cacagtgata aaggaggcag ttttgaagct
9181 gcactatggc aacaatggga ccgacaatcc ctaattatgt ttatcactgc attcttgaat
9241 attgctctcc agttaccgtg tgaaagttct gctgtcgttg tttcagggtt aagaacattg
9301 gttcctcaat cagataatga ggaagcttca accaacccgg ggacatgctc atggtctgat
9361 gagggtaccc cttaataagg ctgactaaaa cactatataa ccttctactt gatcacaata
9421 ctccgtatac ctatcatcat atatttaatc aagacgatat cctttaaaac ttattcagta
9481 ctataatcac tctcgtttca aattaataag atgtgcatga ttgccctaat atatgaagag
9541 gtatgataca accctaacag tgatcaaaga aaatcataat ctcgtatcgc tcgtaatata
9601 acctgccaag catacctctt gcacaaagtg attcttgtac acaaataatg ttttactcta
9661 caggaggtag caacgatcca tcccatcaaa aaataagtat ttcatgactt actaatgatc
9721 tcttaaaata ttaagaaaaa ctgacggaac ataaattctt tatgcttcaa gctgtggagg
9781 aggtgtttgg tattggctat tgttatatta caatcaataa caagcttgta aaaatattgt
9841 tcttgtttca agaggtagat tgtgaccgga aatgctaaac taatgatgaa gattaatgcg
9901 gaggtctgat aagaataaac cttattattc agattaggcc ccaagaggca ttcttcatct
9961 ccttttagca aagtactatt tcagggtagt ccaattagtg gcacgtcttt tagctgtata
10021 tcagtcgccc ctgagatacg ccacaaaagt gtctctaagc taaattggtc tgtacacatc
10081 ccatacattg tattaggggc aataatatct aattgaactt agccgtttaa aatttagtgc
10141 ataaatctgg gctaacacca ccaggtcaac tccattggct gaaaagaagc ttacctacaa
10201 cgaacatcac tttgagcgcc ctcacaatta aaaaatagga acgtcgttcc aacaatcgag
10261 cgcaaggttt caaggttgaa ctgagagtgt ctagacaaca aaatattgat actccagaca
10321 ccaagcaaga cctgagaaaa aaccatggct aaagctacgg gacgatacaa tctaatatcg
10381 cccaaaaagg acctggagaa aggggttgtc ttaagcgacc tctgtaactt cttagttagc
10441 caaactattc aggggtggaa ggtttattgg gctggtattg agtttgatgt gactcacaaa
10501 ggaatggccc tattgcatag actgaaaact aatgactttg cccctgcatg gtcaatgaca
10561 aggaatctct ttcctcattt atttcaaaat ccgaattcca caattgaatc accgctgtgg
10621 gcattgagag tcatccttgc agcagggata caggaccagc tgattgacca gtctttgatt
10681 gaacccttag caggagccct tggtctgatc tctgattggc tgctaacaac caacactaac
10741 catttcaaca tgcgaacaca acgtgtcaag gaacaattga gcctaaaaat gctgtcgttg
10801 attcgatcca atattctcaa gtttattaac aaattggatg ctctacatgt cgtgaactac
10861 aacggattgt tgagcagtat tgaaattgga actcaaaatc atacaatcat cataactcga
10921 actaacatgg gttttctggt ggagctccaa gaacccgaca aatcggcaat gaaccgcatg
10981 aagcctgggc cggcgaaatt ttccctcctt catgagtcca cactgaaagc atttacacaa
11041 ggatcctcga cacgaatgca aagtttgatt cttgaattta atagctctct tgctatctaa
11101 ctaaggtaga atacttcata ttgagctaac tcatatatgc tgactcaata gttatcttga
11161 catctctgct ttcataatca gatatataag cataataaat aaatactcat atttcttgat
11221 aatttgttta accacagata aatcctcact gtaagccagc ttccaagttg acacccttac
11281 aaaaaccagg actcagaatc cctcaaacaa gagattccaa gacaacatca tagaattgct
11341 ttattatatg aataagcatt ttatcaccag aaatcctata tactaaatgg ttaattgtaa
11401 ctgaacccgc aggtcacatg tgttaggttt cacagattct atatattact aactctatac
11461 tcgtaattaa cattagataa gtagattaag aaaaaagcct gaggaagatt aagaaaaact
11521 gcttattggg tctttccgtg ttttagatga agcagttgaa attcttcctc ttgatattaa
11581 atggctacac aacataccca atacccagac gctaggttat catcaccaat tgtattggac
11641 caatgtgacc tagtcactag agcttgcggg ttatattcat catactccct taatccgcaa
11701 ctacgcaact gtaaactccc gaaacatatc taccgtttga aatacgatgt aactgttacc
11761 aagttcttga gtgatgtacc agtggcgaca ttgcccatag atttcatagt cccagttctt
11821 ctcaaggcac tgtcaggcaa tggattctgt cctgttgagc cgcggtgcca acagttctta
11881 gatgaaatca ttaagtacac aatgcaagat gctctcttct tgaaatatta tctcaaaaat
11941 gtgggtgctc aagaagactg tgttgatgaa cactttcaag agaaaatctt atcttcaatt
12001 cagggcaatg aatttttaca tcaaatgttt ttctggtatg atctggctat tttaactcga
12061 aggggtagat taaatcgagg aaactctaga tcaacatggt ttgttcatga tgatttaata
12121 gacatcttag gctatgggga ctatgttttt tggaagatcc caatttcaat gttaccactg
12181 aacacacaag gaatccccca tgctgctatg gactggtatc aggcatcagt attcaaagaa
12241 gcggttcaag ggcatacaca cattgtttct gtttctactg ccgacgtctt gataatgtgc
12301 aaagatttaa ttacatgtcg attcaacaca actctaatct caaaaatagc agagattgag
12361 gatccagttt gttctgatta tcccaatttt aagattgtgt ctatgcttta ccagagcgga
12421 gattacttac tctccatatt agggtctgat gggtataaaa ttattaagtt cctcgaacca
12481 ttgtgcttgg ccaaaattca attatgctca aagtacactg agaggaaggg ccgattctta
12541 acacaaatgc atttagctgt aaatcacacc ctagaagaaa ttacagaaat gcgtgcacta
12601 aagccttcac aggctcaaaa gatccgtgaa ttccatagaa cattgataag gctggagatg
12661 acgccacaac aactttgtga gctattttcc attcaaaaac actgggggca tcctgtgcta
12721 catagtgaaa cagcaatcca aaaagttaaa aaacatgcta cggtgctaaa agcattacgc
12781 cctatagtga ttttcgagac atactgtgtt tttaaatata gtattgccaa acattatttt
12841 gatagtcaag gatcttggta cagtgttact tcagatagga atctaacacc gggtcttaat
12901 tcttatatca aaagaaatca attccctccg ttgccaatga ttaaagaact actatgggaa
12961 ttttaccacc ttgaccaccc tccacttttc tcaaccaaaa ttattagtga cttaagtatt
13021 tttataaaag acagagctac cgcagtagaa aggacatgct gggatgcagt attcgagcct
13081 aatgttctag gatataatcc acctcacaaa tttagtacta aacgtgtacc ggaacaattt
13141 ttagagcaag aaaacttttc tattgagaat gttctttcct acgcacaaaa actcgagtat
13201 ctactaccac aatatcggaa cttttctttc tcattgaaag agaaagagtt gaatgtaggt
13261 agaaccttcg gaaaattgcc ttatccgact cgcaatgttc aaacactttg tgaagctctg
13321 ttagctgatg gtcttgctaa agcatttcct agcaatatga tggtagttac ggaacgtgag
13381 caaaaagaaa gcttattgca tcaagcatca tggcaccaca caagtgatga ttttggtgaa
13441 catgccacag ttagagggag tagctttgta actgatttag agaaatacaa tcttgcattt
13501 agatatgagt ttacagcacc ttttatagaa tattgcaacc gttgctatgg tgttaagaat
13561 gtttttaatt ggatgcatta tacaatccca cagtgttata tgcatgtcag tgattattat
13621 aatccaccac ataacctcac actggagaat cgagacaacc cccccgaagg gcctagttca
13681 tacaggggtc atatgggagg gattgaagga ctgcaacaaa aactctggac aagtatttca
13741 tgtgctcaaa tttctttagt tgaaattaag actggtttta agttacgctc agctgtgatg
13801 ggtgacaatc agtgcattac tgttttatca gtcttcccct tagagactga cgcagacgag
13861 caggaacaga gcgccgaaga caatgcagcg agggtggccg ccagcctagc aaaagttaca
13921 agtgcctgtg gaatcttttt aaaacctgat gaaacatttg tacattcagg ttttatctat
13981 tttggaaaaa aacaatattt gaatggggtc caattgcctc agtcccttaa aacggctaca
14041 agaatggcac cattgtctga tgcaattttt gatgatcttc aagggaccct ggctagtata
14101 ggcactgctt ttgagcgatc catctctgag acacgacata tctttccttg caggataacc
14161 gcagctttcc atacgttttt ttcggtgaga atcttgcaat atcatcatct cgggttcaat
14221 aaaggttttg accttggaca gttaacactc ggcaaacctc tggatttcgg aacaatatca
14281 ttggcactag cggtaccgca ggtgcttgga gggttatcct tcttgaatcc tgagaaatgt
14341 ttctaccgga atctaggaga tccagttacc tcaggcttat tccagttaaa aacttatctc
14401 cgaatgattg agatggatga tttattctta cctttaattg cgaagaaccc tgggaactgc
14461 actgccattg actttgtgct aaatcctagc ggattaaatg tccctgggtc gcaagactta
14521 acttcatttc tgcgccagat tgtacgcagg accatcaccc taagtgcgaa aaacaaactt
14581 attaatacct tatttcatgc gtcagctgac ttcgaagacg aaatggtttg taaatggcta
14641 ttatcatcaa ctcctgttat gagtcgtttt gcggccgata tcttttcacg cacgccgagc
14701 gggaagcgat tgcaaattct aggatacctg gaaggaacac gcacattatt agcctctaag
14761 atcatcaaca ataatacaga gacaccggtt ttggacagac tgaggaaaat aacattgcaa
14821 aggtggagcc tatggtttag ttatcttgat cattgtgata atatcctggc ggaggcttta
14881 acccaaataa cttgcacagt tgatttagca cagattctga gggaatattc atgggctcat
14941 attttagagg gaagacctct tattggagcc acactcccat gtatgattga gcaattcaaa
15001 gtgttttggc tgaaacccta cgaacaatgt ccgcagtgtt caaatgcaaa gcaaccaggt
15061 gggaaaccat tcgtgtcagt ggcagtcaag aaacatattg ttagtgcatg gccgaacgca
15121 tcccgaataa gctggactat cggggatgga atcccataca ttggatcaag gacagaagat
15181 aagataggac aacctgctat taaaccaaaa tgtccttccg cagccttaag agaggccatt
15241 gaattggcgt cccgtttaac atgggtaact caaggcagtt cgaacagtga cttgctaata
15301 aaaccatttt tggaagcacg agtaaattta agtgttcaag aaatacttca aatgacccct
15361 tcacattact caggaaatat tgttcacagg tacaacgatc aatacagtcc tcattctttc
15421 atggccaatc gtatgagtaa ttcagcaacg cgattgattg tttctacaaa cactttaggt
15481 gagttttcag gaggtggcca gtctgcacgc gacagcaata ttattttcca gaatgttata
15541 aattatgcag ttgcactgtt cgatattaaa tttagaaaca ctgaggctac agatatccaa
15601 tataatcgtg ctcaccttca tctaactaag tgttgcaccc gggaagtacc agctcagtat
15661 ttaacataca catctacatt ggatttagat ttaacaagat accgagaaaa cgaattgatt
15721 tatgacagta atcctctaaa aggaggactc aattgcaata tctcattcga taatccattt
15781 ttccaaggta aacggctgaa cattatagaa gatgatctta ttcgactgcc tcacttatct
15841 ggatgggagc tagccaagac catcatgcaa tcaattattt cagatagcaa caattcatct
15901 acagacccaa ttagcagtgg agaaacaaga tcattcacta cccatttctt aacttatccc
15961 aagataggac ttctgtacag ttttggggcc tttgtaagtt attatcttgg caatacaatt
16021 cttcggacta agaaattaac acttgacaat tttttatatt acttaactac tcaaattcat
16081 aatctaccac atcgctcatt gcgaatactt aagccaacat tcaaacatgc aagcgttatg
16141 tcacggttaa tgagtattga tcctcatttt tctatttaca taggcggtgc tgcaggtgac
16201 agaggactct cagatgcggc caggttattt ttgagaacgt ccatttcatc ttttcttaca
16261 tttgtaaaag aatggataat taatcgcgga acaattgtcc ctttatggat agtatatccg
16321 ctagagggtc aaaacccaac acctgtgaat aattttctct atcagatcgt agaactgctg
16381 gtgcatgatt catcaagaca acaggctttt aaaactacca taagtgatca tgtacatcct
16441 cacgacaatc ttgtttacac atgtaagagt acagccagca atttcttcca tgcatcattg
16501 gcgtactgga ggagcagaca cagaaacagc aaccgaaaat acttggcaag agactcttca
16561 actggatcaa gcacaaacaa cagtgatggt catattgaga gaagtcaaga acaaaccacc
16621 agagatccac atgatggcac tgaacggaat ctagtcctac aaatgagcca tgaaataaaa
16681 agaacgacaa ttccacaaga aaacacgcac cagggtccgt cgttccagtc ctttctaagt
16741 gactctgctt gtggtacagc aaatccaaaa ctaaatttcg atcgatcgag acacaatgtg
16801 aaatttcagg atcataactc ggcatccaag agggaaggtc atcaaataat ctcacaccgt
16861 ctagtcctac ctttctttac attatctcaa gggacacgcc aattaacgtc atccaatgag
16921 tcacaaaccc aagacgagat atcaaagtac ttacggcaat tgagatccgt cattgatacc
16981 acagtttatt gtagatttac cggtatagtc tcgtccatgc attacaaact tgatgaggtc
17041 ctttgggaaa tagagagttt caagtcggct gtgacgctag cagagggaga aggtgctggt
17101 gccttactat tgattcagaa ataccaagtt aagaccttat ttttcaacac gctagctact
17161 gagtccagta tagagtcaga aatagtatca ggaatgacta ctcctaggat gcttctacct
17221 gttatgtcaa aattccataa tgaccaaatt gagattattc ttaacaactc agcaagccaa
17281 ataacagaca taacaaatcc tacttggttt aaagaccaaa gagcaaggct acctaagcaa
17341 gtcgaggtta taaccatgga tgcagagaca acagagaata taaacagatc gaaattgtac
17401 gaagctgtat ataaattgat cttacaccat attgatccta gcgtattgaa agcagtggtc
17461 cttaaagtct ttctaagtga tactgagggt atgttatggc taaatgataa tttagccccg
17521 ttttttgcca ctggttattt aattaagcca ataacgtcaa gtgctagatc tagtgagtgg
17581 tatctttgtc tgacgaactt cttatcaact acacgtaaga tgccacacca aaaccatctc
17641 agttgtaaac aggtaatact tacggcattg caactgcaaa ttcaacgaag cccatactgg
17701 ctaagtcatt taactcagta tgctgactgt gagttacatt taagttatat ccgccttggt
17761 tttccatcat tagagaaagt actataccac aggtataacc tcgtcgattc aaaaagaggt
17821 ccactagtct ctatcactca gcacttagca catcttagag cagagattcg agaattaact
17881 aatgattata atcaacagcg acaaagtcgg actcaaacat atcactttat tcgtactgca
17941 aaaggacgaa tcacaaaact agtcaatgat tatttaaaat tctttcttat tgtgcaagca
18001 ttaaaacata atgggacatg gcaagctgag tttaagaaat taccagagtt gattagtgtg
18061 tgcaataggt tctaccatat tagagattgc aattgtgaag aacgtttctt agttcaaacc
18121 ttatatttac atagaatgca ggattctgaa gttaagctta tcgaaaggct gacagggctt
18181 ctgagtttat ttccggatgg tctctacagg tttgattgaa ttaccgtgca tagtatcctg
18241 atacttgcaa aggttggtta ttaacataca gattataaaa aactcataaa ttgctctcat
18301 acatcatatt gatctaatct caataaacaa ctatttaaat aacgaaagga gtccctatat
18361 tatatactat atttagcctc tctccctgcg tgataatcaa aaaattcaca atgcagcatg
18421 tgtgacatat tactgccgca atgaatttaa cgcaacataa taaactctgc actctttata
18481 attaagcttt aacgaaaggt ctgggctcat attgttattg atataataat gttgtatcaa
18541 tatcctgtca gatggaatag tgttttggtt gataacacaa cttcttaaaa caaaattgat
18601 ctttaagatt aagtttttta taattatcat tactttaatt tgtcgtttta aaaacggtga
18661 tagccttaat ctttgtgtaa aataagagat taggtgtaat aaccttaaca tttttgtcta
18721 gtaagctact atttcataca gaatgataaa attaaaagaa aaggcaggac tgtaaaatca
18781 gaaatacctt ctttacaata tagcagacta gataataatc ttcgtgttaa tgataattaa
18841 gacattgacc acgctcatca gaaggctcgc cagaataaac gttgcaaaaa ggattcctgg
18901 aaaaatggtc gcacacaaaa atttaaaaat aaatctattt cttctttttt gtgtgtcca
//
.jpg)

.jpg)












.jpg)










.jpg)
.jpg)