The main function of telomere is to protect chromosome ends from degradation and avoid genetic instability arising from the fusion with other chromosomes at the termini. Telomeres at the ends of chromosomes are comprised of numerous repeats of simple DNA sequence such as TTAGGG in the case of humans. To prevent DNA repair/recombination from occurring at the chromosome ends, the DNA sequence repeats and a single stranded 3’-overhang of telomere fold back on itself to form a loop (T loop) with the single strand invading the duplex to anneal with one of the two strands (D loop) (Xu et al., 2016). This ‘capping’ function of telomere is mediated by Shelterin proteins, which incudes TRF1, TRF2, POT1, RAP1 and others.
In most organisms, the length of telomere decreases after each round of DNA replication in normal cells. The loss of telomere occurs as the terminal DNA sequence occupied by the RNA primer towards the end of the lagging strand (Richter et al., 2007) cannot be replicated by DNA polymerase (though other factors such as oxidative stress may also contribute). However, the progressive shortening of telomeres can be reversed through telomerase, which regenerates repeat sequences. Telomerase is comprised of telomerase RNA (TERC), telomerase reverse transcriptase (TERT) and several associating proteins (Venteicher et al., 2008; Xu et al., 2016). To extend shorter telomeres, TERT uses TERC’s template to add sequence repeats at the 3' end. Whereas most normal somatic cells express little telomerase, TERT activity is up-regulated in continuously dividing stem cells and ectopically expressing hTERT immortalizes non-stem cells, indicating that telomeres may affect cell’s lifespan. Consistently, an elevated telomerase activity was observed in most cancer specimens (Kim et al., 1994).
Several highly sensitive assays have been developed to diagnose the telomere status. First, to survey the altered level of telomerase activity in cancer versus normal cells, Telomere Repeat Amplification Protocol (TRAP) assay was developed (Kim et al. 1994). It involves extending the substrate oligonucleotide by telomerase, followed by PCR amplification using alternate primers, and separation by gel electrophoresis to visualize the extended products (Mender et al 2015a).

Second, the loss of telomere function due to defective shelterin proteins (see above) or very short telomeric repeats elicits
Third, to determine the telomere length of individual chromosomes, Fluorescence In Situ Hybriization (FISH) was performed. Investigators at the British Columbia Cancer Agency (Canada) analyzed human metaphase or interphase chromosomes in fetal liver, adult bone marrow and chronic myeloid leukemia (CML) cells using a PNA (peptide nucleic acid)-based oligonucleotide probe recognizing the TTAGGG repeats. The observed fluorescence intensities of sister chromatids’ telomeres were comparable, indicative of similar number of the repeats. The mean telomerase fluorescence intensity correlated with the mean size of the ‘terminal restriction fragment’ (see below) (Lansdorp et al.., 1996). Quenching by red blood cells (RBC) or autofluorescing molecules in granulocytes may affect the fluorescence level, however (Baerlocher et al., 2002).
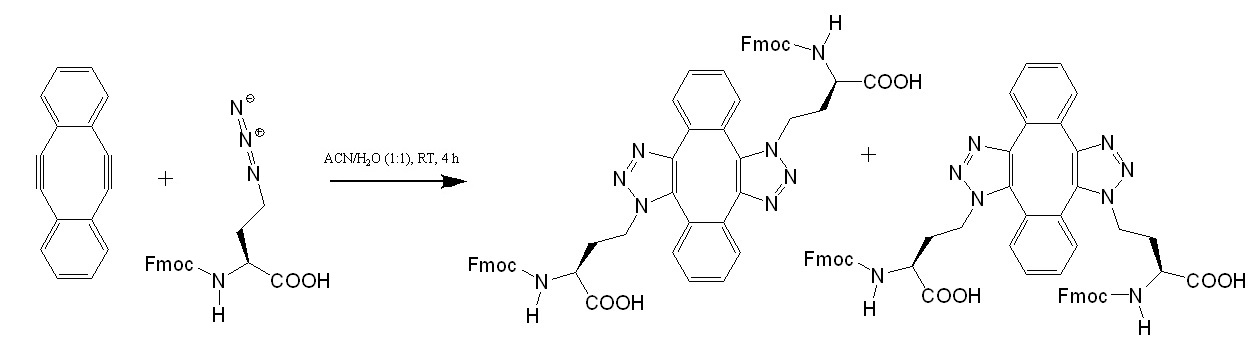
Terminal Restriction Fragment (TRF) represents an alternate method to directly measure the length of telomeres (Mender et al 2015c). After cleaving the genomic DNA with a restriction endonuclease, the resultant fragments (~800 bp) were subjected to Southern blot analysis. To increase detection sensitivity for analyzing small amounts of tumor DNA and avoid hazards associated with radioactive labels, a modified TRF assay utilizing digoxigenin (DIG)-labeled probes was developed at the University of Texas Southwestern Medical Center (Lai et al., 2016). To increase signal, the probe was labeled internally. To incorporate multiple DIG labels, a template oligonucleotide encoding the complementary sequence of telomeric repeats was prepared, to which a primer was hybridized to extend using a mixture of DIG-dUTP and dNTPs. After the elongation/modification, the resultant DNA was treated (5’ à 3’) with exonuclease to yield single stranded DIG-labeled probe. To prevent degradation, bridged nucleic acid (BNA) analogues were incorporated at the 3’ terminus of the primer, which was used to generate the probe. The enhanced sensitivity of the method was demonstrated using human cervical cancer-derived HeLa cells.
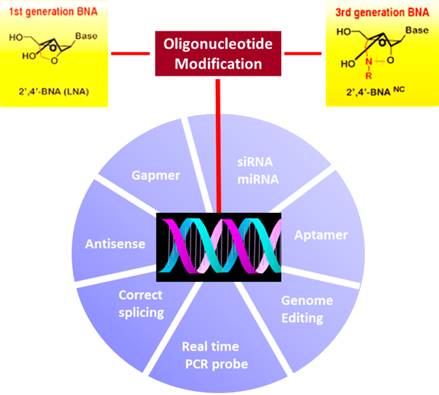
Bio-Synthesis, Inc. provides extensive options for the application of various modified nucleosides for research or therapy purposes. It specializes in oligonucleotide modification and provides an extensive array of chemically modified nucleoside analogues (over ~200). For instance, we provide digoxigenin oligonucleotide labeling services at 5', 3' and internally using NHS ester cross-linking chemistry that reacts with an amine group to form an amide. The digoxigenin-labeld probes could be used for in situ hybridization, Northern or Southern blot analysis. For bridged nucleic acid (BNA), it has recently acquired a license from BNA Inc. of Osaka, Japan, for the manufacturing and distribution of BNANC, a third generation of BNA oligonucleotides. Bio-Synthesis, Inc. has recently entered into collaborative agreement with Bind Therapeutics, Inc. to synthesize miR-21 blocker using BNA. The BNA technology that we offer provides superior, unequalled advantages in base stacking, binding affinity, aqueous solubility and nuclease resistance. More importantly, BNA oligonucleotide exhibits lesser toxicity than other modified nucleotides for clinical application.
https://www.biosyn.com/digoxigenin-oligo-labeling.aspx#!
References
Baerlocher GM, Mak J, Tien T, Lansdorp PM. Telomere length measurement by fluorescence in situ hybridization and flow cytometry: tips and pitfalls. (2002) Cytometry. 47:89-99. PMID: 11813198
Kim NW, Piatyszek MA, Prowse KR, Harley CB, West MD, Ho PL, Coviello GM, Wright WE, Weinrich SL, Shay JW. Specific association of human telomerase activity with immortal cells and cancer. (1994). Science 266:2011-5. PMID: 7605428 DOI: 10.1126/science.7605428
Lai TP, Wright WE, Shay JW. Generation of digoxigenin-incorporated probes to enhance DNA detection sensitivity. (2016) Biotechniques. 60:306-9. doi: 10.2144/000114427. PMID: 27286808
Lansdorp PM, Verwoerd NP, van de Rijke FM, Dragowska V, Little MT, Dirks RW, Raap AK, Tanke HJ. Heterogeneity in telomere length of human chromosomes. (1996) Hum Mol Genet. 5:685-91. PMID: 8733138
Mender I, Shay JW. Telomerase Repeated Amplification Protocol (TRAP). (2015a) Bio Protoc. 5(22). pii: e1657. PMID: 27182535
Mender I, Shay JW. Telomere Dysfunction Induced Foci (TIF) Analysis. (2015b) Bio Protoc. 5(22). pii: e1656. PMID: 27500188
Mender I, Shay JW. Telomere Restriction Fragment (TRF) Analysis. (2015c) Bio Protoc. 5(22). pii: e1658. PMID: 27500189
Richter T, von Zglinicki T. A continuous correlation between oxidative stress and telomere shortening in fibroblasts. (2007) Exp Gerontol. 42:1039-42. PMID: 17869047 DOI: 10.1016/j.exger.2007.08.005
Venteicher A.S., Meng Z., Mason P.J., Veenstra T.D., Artandi S.E. Identification of APTases pontin and reptin as telomerase components essential for holoenzyme assembly. (2008). Cell 132:945–957. PMID: 18358808 PMCID: PMC2291539 DOI: 10.1016/j.cell.2008.01.019
Xu Y, Goldkorn A. Telomere and telomerase therapeutics in cancer. (2016). Genes (Basel) 7: 22. PMCID: PMC4929421 PMID: 27240403


VKQNTLKLAT.jpg)



.jpg)